Руководство по миграции с Amazon Redshift на ClickHouse
Введение
Amazon Redshift — это популярное облачное решение для хранения данных, которое является частью предложений Amazon Web Services. Этот руководств представляет различные подходы к миграции данных из экземпляра Redshift в ClickHouse. Мы рассмотрим три варианта:
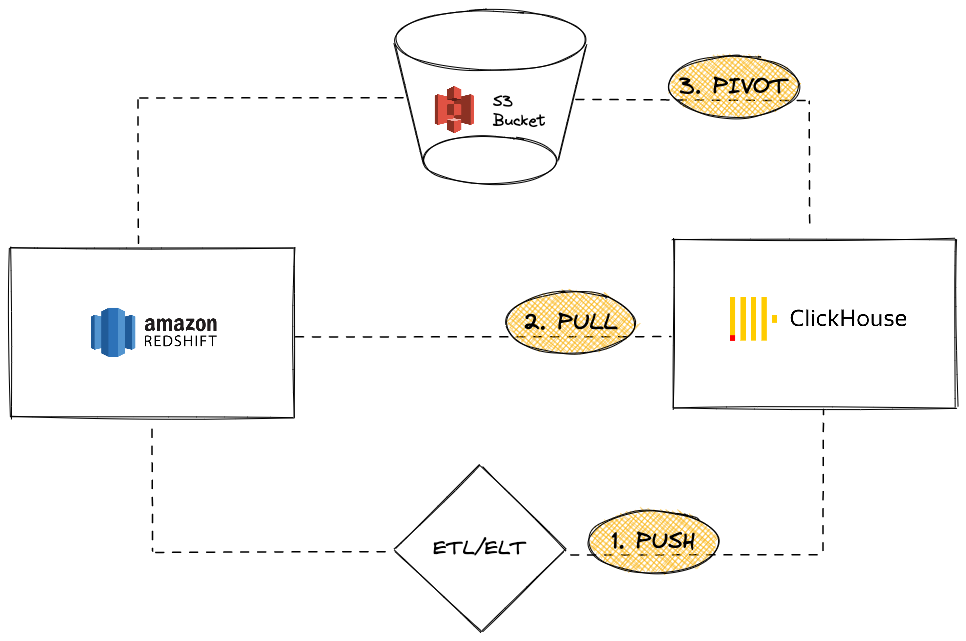
С точки зрения экземпляра ClickHouse, вы можете:
-
PUSH данные в ClickHouse с помощью стороннего инструмента или сервиса ETL/ELT
-
PULL данные из Redshift, используя ClickHouse JDBC Bridge
-
PIVOT с использованием объектного хранилища S3 по логике "Сначала выгрузить, затем загрузить"
Мы использовали Redshift в качестве источника данных в этом учебном пособии. Тем не менее, представленные здесь подходы к миграции не эксклюзивны для Redshift, и аналогичные шаги могут быть выведены для любого совместимого источника данных.
Отправка данных из Redshift в ClickHouse
В сценарии отправки идея состоит в том, чтобы использовать сторонний инструмент или сервис (либо собственный код, либо ETL/ELT), чтобы отправить ваши данные в экземпляр ClickHouse. Например, вы можете использовать программное обеспечение, такое как Airbyte, для перемещения данных между вашим экземпляром Redshift (как источником) и ClickHouse в качестве назначения (см. наше руководство по интеграции для Airbyte)

Плюсы
- Это может использовать существующий каталог коннекторов программного обеспечения ETL/ELT.
- Встроенные возможности для синхронизации данных (добавление/перезапись/инкрементная логика).
- Возможность реализации сценариев преобразования данных (например, см. наше руководство по интеграции для dbt).
Минусы
- Пользователи должны настроить и поддерживать инфраструктуру ETL/ELT.
- В архитектуру вводится сторонний элемент, который может стать потенциальным узким местом по масштабируемости.
Получение данных из Redshift в ClickHouse
В сценарии получения идея состоит в том, чтобы использовать ClickHouse JDBC Bridge для прямого подключения к кластеру Redshift из экземпляра ClickHouse и выполнения запросов INSERT INTO ... SELECT:

Плюсы
- Универсальность для всех совместимых с JDBC инструментов
- Элегантное решение для выполнения запросов к нескольким внешним источникам данных из ClickHouse
Минусы
- Требуется экземпляр ClickHouse JDBC Bridge, который может стать потенциальным узким местом по масштабируемости
Несмотря на то, что Redshift основан на PostgreSQL, использование функции таблицы PostgreSQL или движка таблицы ClickHouse невозможно, так как ClickHouse требует версию PostgreSQL 9 или выше, а API Redshift основан на более ранней версии (8.x).
Учебное пособие
Чтобы использовать этот вариант, вам нужно настроить ClickHouse JDBC Bridge. ClickHouse JDBC Bridge — это отдельное Java-приложение, которое обрабатывает соединение JDBC и выполняет функции прокси между экземпляром ClickHouse и источниками данных. В этом учебном пособии мы использовали предварительно заполненный экземпляр Redshift с образцовой базой данных.
Развертывание ClickHouse JDBC Bridge
Разверните ClickHouse JDBC Bridge. Для получения дополнительной информации см. наше руководство пользователя по JDBC для внешних источников данных
Если вы используете ClickHouse Cloud, вам нужно будет запустить свой ClickHouse JDBC Bridge в отдельной среде и подключиться к ClickHouse Cloud, используя функцию remoteSecure
Настройка источника данных Redshift
Настройте источник данных Redshift для ClickHouse JDBC Bridge. Например, /etc/clickhouse-jdbc-bridge/config/datasources/redshift.json
Выполнение запросов к экземпляру Redshift из ClickHouse
После развертывания и запуска ClickHouse JDBC Bridge вы можете начать выполнять запросы к вашему экземпляру Redshift из ClickHouse
Импорт данных из Redshift в ClickHouse
В следующем разделе мы покажем, как импортировать данные, используя оператор INSERT INTO ... SELECT
Свод данных из Redshift в ClickHouse с использованием S3
В этом сценарии мы экспортируем данные в S3 в промежуточном сводном формате и на втором этапе загружаем данные из S3 в ClickHouse.
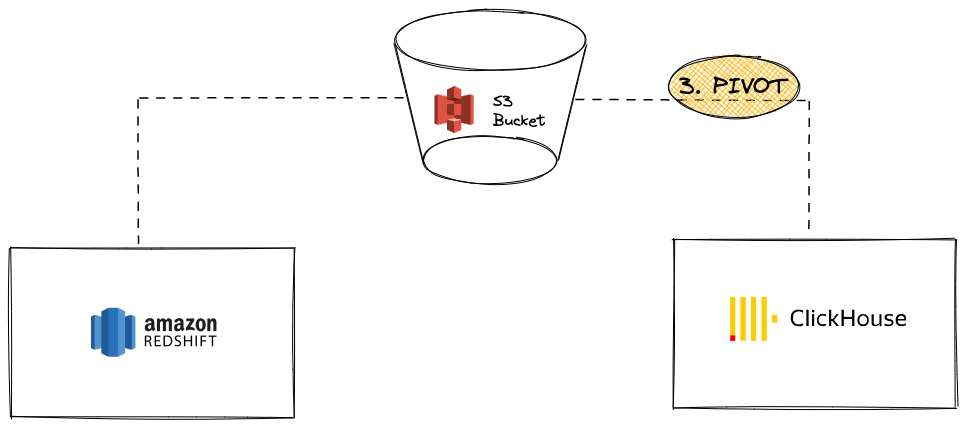
Плюсы
- И Redshift, и ClickHouse имеют мощные функции интеграции с S3.
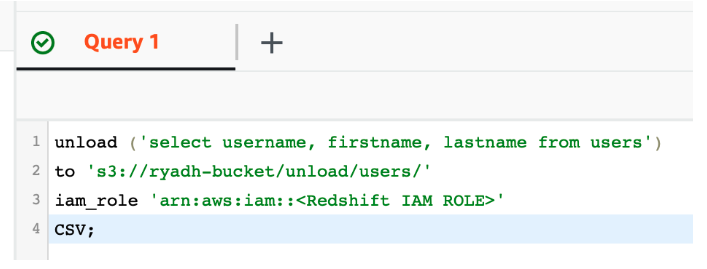
- Использует существующие функции, такие как команда Redshift
UNLOADи функцию таблицы/движок таблицы ClickHouse для S3. - Безшовно масштабируется благодаря параллельным чтениям и высоким возможностям пропускной способности при передаче данных в/из S3 в ClickHouse.
- Может использовать сложные и сжатые форматы, такие как Apache Parquet.
Минусы
- Два шага в процессе (выгрузка из Redshift, затем загрузка в ClickHouse).
Учебное пособие

Создание таблицы в ClickHouse
Создайте таблицу в ClickHouse:
В качестве альтернативы ClickHouse может попытаться вывести структуру таблицы, используя CREATE TABLE ... EMPTY AS SELECT:
Это особенно хорошо работает, когда данные находятся в формате, содержащем информацию о типах данных, например, Parquet.
Загрузка файлов S3 в ClickHouse
Загрузите файлы S3 в ClickHouse, используя оператор INSERT INTO ... SELECT:
В этом примере использовался CSV в качестве сводного формата. Однако для производственных рабочих нагрузок мы рекомендуем использовать Apache Parquet как лучший вариант для больших миграций, так как он поддерживает сжатие и может снизить затраты на хранение, сокращая время передачи. (По умолчанию для каждого группы строк применяется сжатие с помощью SNAPPY). ClickHouse также использует ориентированность колонок Parquet для ускорения приемки данных.
