Репликация данных
В этом примере вы научитесь настраивать простой кластер ClickHouse, который
реплицирует данные. Существует пять сконфигурированных серверов. Два используются для хранения
копий данных. Остальные три сервера используются для координации репликации
данных.
Архитектура кластера, который вы будете настраивать, показана ниже:
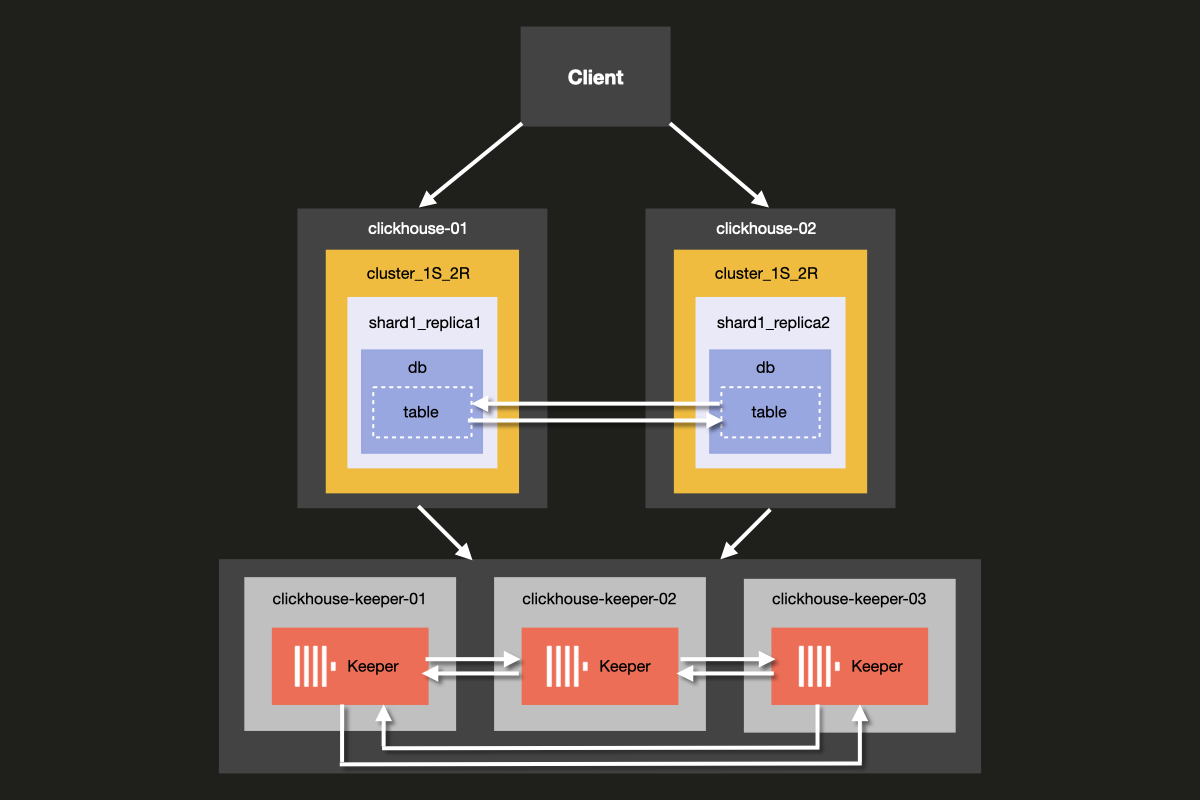
Хотя возможно запускать ClickHouse Server и ClickHouse Keeper на одном и том же сервере, мы настоятельно рекомендуем использовать выделенные хосты для ClickHouse Keeper в производственных средах, что является подходом, который мы продемонстрируем в этом примере.
Серверы Keeper могут быть меньшими, и обычно 4 ГБ ОП достаточно для каждого сервера Keeper, пока ваши серверы ClickHouse не вырастут в размерах.
Предварительные требования
- Вы ранее настроили локальный сервер ClickHouse
- Вы знакомы с основными концепциями конфигурации ClickHouse, такими как файлы конфигурации
- У вас установлен Docker на вашем компьютере
Настройка структуры каталогов и тестовой среды
Следующие шаги помогут вам настроить кластер с нуля. Если вы предпочитаете пропустить эти шаги и сразу перейти к запуску кластера, вы можете получить примерные файлы из репозитория примеров
В этом уроке вы будете использовать Docker compose для
настройки кластера ClickHouse. Эта настройка может быть изменена для работы
с отдельными локальными машинами, виртуальными машинами или облачными инстансами.
Запустите следующие команды для настройки структуры каталогов для этого примера:
Добавьте следующий файл docker-compose.yml в каталог cluster_1S_2R:
Создайте следующие подкаталоги и файлы:
- Директория
config.dсодержит файл конфигурации сервера ClickHouseconfig.xml, в котором определяется пользовательская конфигурация для каждого узла ClickHouse. Эта конфигурация объединяется с конфигурацией по умолчанию из файлаconfig.xml, который поставляется с каждой установкой ClickHouse. - Директория
users.dсодержит файл конфигурации пользователейusers.xml, в котором определяется пользовательская конфигурация для пользователей. Эта конфигурация объединяется с конфигурацией пользователей ClickHouse по умолчанию из файлаusers.xml, который поставляется с каждой установкой ClickHouse.
Рекомендуется использовать директории config.d и users.d при написании вашей собственной конфигурации, а не изменять конфигурацию по умолчанию в /etc/clickhouse-server/config.xml и etc/clickhouse-server/users.xml.
Строка
Обеспечивает переопределение секций конфигурации, определенных в директориях config.d и users.d, секциями конфигурации по умолчанию, определенными в файлах config.xml и users.xml.
Настройка узлов ClickHouse
Настройка сервера
Теперь измените каждый пустой файл конфигурации config.xml, находящийся в
fs/volumes/clickhouse-{}/etc/clickhouse-server/config.d. Строки, выделенные ниже, необходимо изменить
так, чтобы они были специфичными для каждого узла:
| Каталог | Файл |
|---|---|
fs/volumes/clickhouse-01/etc/clickhouse-server/config.d | config.xml |
fs/volumes/clickhouse-02/etc/clickhouse-server/config.d | config.xml |
Каждый раздел вышеуказанного файла конфигурации объясняется более подробно ниже.
Сеть и логирование
Внешняя связь с сетевым интерфейсом включается активацией настройки listen host. Это гарантирует, что хост сервера ClickHouse доступен для других хостов:
Порт для HTTP API установлен на 8123:
TCP-порт для взаимодействия по нативному протоколу ClickHouse между clickhouse-client и другими нативными инструментами ClickHouse, а также clickhouse-server и другими clickhouse-server установлен на 9000:
Логирование определяется в блоке <logger>. Эта примерная конфигурация предоставляет
вам отладочный лог, который будет обновляться при достижении 1000M трижды:
Для получения дополнительной информации о конфигурации логирования смотрите комментарии, включенные в
стандартный файл конфигурации ClickHouse.
Конфигурация кластера
Конфигурация для кластера настраивается в блоке <remote_servers>.
Здесь определено имя кластера cluster_1S_2R.
Блок <cluster_1S_2R></cluster_1S_2R> определяет структуру кластера,
используя параметры <shard></shard> и <replica></replica>, и служит шаблоном для
распределенных DDL-запросов, которые выполняются по кластеру с использованием
оператора ON CLUSTER. По умолчанию распределенные DDL-запросы разрешены,
но их также можно отключить, установив параметр allow_distributed_ddl_queries.
internal_replication установлено в true, чтобы данные записывались только на одну из реплик.
Для каждого сервера указаны следующие параметры:
| Параметр | Описание | Значение по умолчанию |
|---|---|---|
host | Адрес удаленного сервера. Вы можете использовать как доменное имя, так и адрес IPv4 или IPv6. Если вы укажете домен, сервер выполнит запрос DNS при старте, и результат будет храниться до тех пор, пока сервер работает. Если запрос DNS завершится неудачно, сервер не запустится. Если вы измените запись DNS, необходимо перезапустить сервер. | - |
port | TCP-порт для ведения связи (tcp_port в конфигурации, обычно равен 9000). Не путать с http_port. | - |
Конфигурация Keeper
Секция <ZooKeeper> сообщает ClickHouse, где работает ClickHouse Keeper (или ZooKeeper).
Поскольку мы используем кластер ClickHouse Keeper, каждый <node> кластера должен быть указан,
вместе с его именем хоста и номером порта с помощью тегов <host> и <port> соответственно.
Настройка ClickHouse Keeper объясняется на следующем шаге урока.
Хотя запуск ClickHouse Keeper на том же сервере, что и ClickHouse Server, возможен,
в производственных средах мы настоятельно рекомендуем, чтобы ClickHouse Keeper работал на выделенных хостах.
Конфигурация макросов
Кроме того, секция <macros> используется для определения параметров замены для
реплицированных таблиц. Они перечислены в system.macros и позволяют использовать замену
таких параметров, как {shard} и {replica} в запросах.
Эти значения будут определены уникально в зависимости от структуры кластера.
Конфигурация пользователей
Теперь измените каждый пустой файл конфигурации users.xml, находящийся в
fs/volumes/clickhouse-{}/etc/clickhouse-server/users.d, следующим образом:
| Каталог | Файл |
|---|---|
fs/volumes/clickhouse-01/etc/clickhouse-server/users.d | users.xml |
fs/volumes/clickhouse-02/etc/clickhouse-server/users.d | users.xml |
В этом примере стандартный пользователь настроен без пароля для упрощения.
На практике это не рекомендуется.
В этом примере каждый файл users.xml идентичен для всех узлов кластера.
Настройка ClickHouse Keeper
Настройка Keeper
Чтобы репликация работала, необходимо настроить и сконфигурировать кластер ClickHouse Keeper. ClickHouse Keeper предоставляет систему координации для репликации данных, выступая в качестве замены Zookeeper, который также можно использовать. Однако рекомендуется использовать ClickHouse Keeper, так как он обеспечивает лучшие гарантии и надежность и использует меньше ресурсов, чем ZooKeeper. Для высокой доступности и поддержания кворума рекомендуется запустить как минимум три узла ClickHouse Keeper.
ClickHouse Keeper может работать на любом узле кластера вместе с ClickHouse, хотя рекомендуется запускать его на выделенном узле, что позволяет масштабировать и управлять кластером ClickHouse Keeper независимо от кластера базы данных.
Создайте файлы keeper_config.xml для каждого узла ClickHouse Keeper с помощью следующей команды из корня папки примера:
Измените пустые файлы конфигурации, которые были созданы в каждой директории узла fs/volumes/clickhouse-keeper-{}/etc/clickhouse-keeper. Выделенные строки ниже необходимо изменить так, чтобы они были специфичны для каждого узла:
| Каталог | Файл |
|---|---|
fs/volumes/clickhouse-keeper-01/etc/clickhouse-server/config.d | keeper_config.xml |
fs/volumes/clickhouse-keeper-02/etc/clickhouse-server/config.d | keeper_config.xml |
fs/volumes/clickhouse-keeper-03/etc/clickhouse-server/config.d | keeper_config.xml |
Каждый файл конфигурации будет содержать следующую уникальную конфигурацию (представленную ниже).
server_id, используемый для этого конкретного узла ClickHouse Keeper в кластере, должен быть уникальным и соответствовать значению <id>, определенному в разделе <raft_configuration>.
tcp_port — это порт, используемый клиентами ClickHouse Keeper.
Следующий раздел используется для настройки серверов, которые участвуют в квorum для алгоритма Raft:
ClickHouse Cloud устраняет операционную нагрузку, связанную с управлением шардами и репликами. Платформа автоматически обрабатывает задачи высокой доступности, репликации и принятия решений о масштабировании. Вычисления и хранилище разделены и масштабируются в зависимости от спроса без необходимости в ручной настройке или постоянном обслуживании.
Протестируйте настройку
Убедитесь, что docker работает на вашем компьютере.
Запустите кластер, используя команду docker-compose up из корня каталога cluster_1S_2R:
Вы должны увидеть, как docker начинает загружать образы ClickHouse и Keeper, а затем запускает контейнеры:
Чтобы проверить, что кластер работает, подключитесь к либо clickhouse-01, либо clickhouse-02 и выполните
следующий запрос. Команда для подключения к первому узлу показана:
Если всё прошло успешно, вы увидите приглашение клиента ClickHouse:
Запустите следующий запрос, чтобы проверить, какие топологии кластера определены для каких
хостов:
Запустите следующий запрос, чтобы проверить статус кластера ClickHouse Keeper:
Команда mntr также часто используется для проверки того, что ClickHouse Keeper работает, и для получения информации о состоянии отношений между тремя узлами Keeper. В конфигурации, используемой в этом примере, три узла работают совместно. Узлы будут выбирать лидера, а оставшиеся узлы станут последователями.
Команда mntr предоставляет информацию, связанную с производительностью, а также о том, является ли конкретный узел последователем или лидером.
Возможно, вам потребуется установить netcat, чтобы отправить команду mntr в Keeper. Пожалуйста, смотрите страницу nmap.org для информации о загрузке.
Запустите команду ниже из командной строки на clickhouse-keeper-01, clickhouse-keeper-02 и clickhouse-keeper-03, чтобы проверить статус каждого узла Keeper. Команда для clickhouse-keeper-01 показана ниже:
Ответ ниже показывает пример ответа от узла-последователя:
Ответ ниже показывает пример ответа от узла-лидера:
Теперь вы успешно настроили кластер ClickHouse с одним шардом и двумя репликами.
На следующем шаге вы создадите таблицу в кластере.
Создание базы данных
Теперь, когда вы подтвердили, что кластер настроен и работает, вы
воссоздадите ту же таблицу, что и в уроке по примеру набора данных Цены на недвижимость в Великобритании.
Он состоит примерно из 30 миллионов строк цен, уплаченных за недвижимость в Англии и Уэльсе с 1995 года.
Подключитесь к клиенту каждого хоста, запустив каждую из следующих команд из отдельных терминальных
вкладок или окон:
Вы можете выполнить запрос ниже из клиента clickhouse каждого хоста, чтобы подтвердить, что
пока нет созданных баз данных, кроме стандартных:
Из клиента clickhouse-01 выполните следующий распределенный DDL-запрос, используя
оператор ON CLUSTER, чтобы создать новую базу данных с названием uk:
Вы снова можете выполнить тот же запрос, как и ранее, из клиента каждого хоста,
чтобы подтвердить, что база данных была создана по всему кластеру, несмотря на то,
что запрос выполнялся только на clickhouse-01:
Создание таблицы в кластере
Теперь, когда база данных создана, создайте таблицу в кластере.
Выполните следующий запрос из любого из хост-клиентов:
Обратите внимание, что он идентичен запросу, использованному в исходном операторе CREATE
урока по примеру набора данных Цены на недвижимость в Великобритании,
за исключением оператора ON CLUSTER и использования движка ReplicatedMergeTree.
Оператор ON CLUSTER предназначен для распределенного выполнения DDL (язык определения данных)
запросов таких как CREATE, DROP, ALTER и RENAME, гарантируя, что эти
изменения схемы применяются ко всем узлам в кластере.
Движок ReplicatedMergeTree
работает так же, как и обычный движок таблицы MergeTree, но также будет реплицировать данные.
Вы можете выполнить запрос ниже из клиента либо clickhouse-01, либо clickhouse-02,
чтобы подтвердить, что таблица была создана по всему кластеру:
Вставка данных
Поскольку набор данных большой и его полное считывание занимает несколько минут,
мы вставим только небольшую часть в начале.
Вставьте меньшую часть данных, используя запрос ниже из clickhouse-01:
Обратите внимание, что данные полностью реплицированы на каждом хосте:
Чтобы продемонстрировать, что происходит, когда один из хостов выходит из строя, создайте простую
тестовую базу данных и тестовую таблицу с любого из хостов:
Как и с таблицей uk_price_paid, мы можем вставлять данные с любого хоста:
Но что произойдет, если один из хостов выйдет из строя? Чтобы смоделировать это, остановите
clickhouse-01, выполнив:
Проверьте, что хост вышел из строя, выполнив:
Сейчас, когда clickhouse-01 вышел из строя, вставьте еще одну строку данных в тестовую таблицу
и запросите таблицу:
Теперь перезапустите clickhouse-01 с помощью следующей команды (вы можете выполнить docker-compose ps снова, чтобы подтвердить):
Запросите тестовую таблицу снова из clickhouse-01, выполнив docker exec -it clickhouse-01 clickhouse-client:
Если на этом этапе вы хотите загрузить полный набор данных о ценах на недвижимость в Великобритании
для работы с ним, вы можете выполнить следующие запросы, чтобы это сделать:
Запросите таблицу из clickhouse-02 или clickhouse-01:
Заключение
Преимущество этой топологии кластера заключается в том, что с двумя репликами
ваши данные существуют на двух отдельных хостах. Если один хост выходит из строя,
другая реплика продолжает предоставлять данные без каких-либо потерь. Это устраняет
единые точки отказа на уровне хранения.
Когда один хост выходит из строя, оставшаяся реплика все еще может:
- Обрабатывать запросы на чтение без перерывов
- Принимать новые записи (в зависимости от ваших настроек согласованности)
- Поддерживать доступность сервиса для приложений
Когда вышедший из строя хост возвращается в сеть, он может:
- Автоматически синхронизировать отсутствующие данные с рабочей репликой
- Возобновить нормальную работу без ручного вмешательства
- Быстро восстановить полную избыточность
В следующем примере мы рассмотрим, как настроить кластер с двумя шарами, но
только с одной репликой.
