Используйте индексы пропуска данных, где это уместно
Индексы пропуска данных следует рассматривать, когда были соблюдены предыдущие лучшие практики, т.е. типы оптимизированы, выбран хороший первичный ключ и использованы материализованные представления.
Эти типы индексов могут использоваться для ускорения производительности запросов при условии, что они используются с пониманием того, как они работают.
ClickHouse предоставляет мощный механизм, называемый индексы пропуска данных, который может значительно сократить объем сканируемых данных во время выполнения запроса - особенно когда первичный ключ не полезен для конкретного условия фильтрации. В отличие от традиционных баз данных, которые полагаются на вторичные индексы на основе строк (например, B-деревья), ClickHouse является столбцовой базой данных и не хранит местоположения строк таким образом, чтобы поддерживать такие структуры. Вместо этого он использует индексы пропуска, которые помогают избежать чтения блоков данных, которые гарантированно не соответствуют условиям фильтрации запроса.
Индексы пропуска работают, храня метаданные о блоках данных - таких как минимальные/максимальные значения, наборы значений или представления фильтра Блума - и используют эти метаданные во время выполнения запроса, чтобы определить, какие блоки данных можно пропустить. Они применяются только к семейству MergeTree движков таблиц и определяются с помощью выражения, типа индекса, имени и гранулярности, которая определяет размер каждого индексируемого блока. Эти индексы хранятся вместе с данными таблицы и используются, когда фильтр запроса соответствует выражению индекса.
Существует несколько типов индексов пропуска данных, каждый из которых подходит для различных типов запросов и распределения данных:
- minmax: Отслеживает минимальное и максимальное значение выражения для каждого блока. Идеально для диапазонных запросов по слабо отсортированным данным.
- set(N): Отслеживает набор значений до указанного размера N для каждого блока. Эффективен для колонок с низкой кардинальностью на блоки.
- bloom_filter: Вероятностно определяет, существует ли значение в блоке, позволяя быстро и приблизительно фильтровать на принадлежность множеству. Эффективен для оптимизации запросов, ищущих «иглу в стоге сена», где требуется положительное совпадение.
- tokenbf_v1 / ngrambf_v1: Специализированные варианты фильтров Блума, предназначенные для поиска токенов или последовательностей символов в строках - особенно полезны для данных логов или случаев поиска текста.
Хотя индексы пропуска мощные, их необходимо использовать с осторожностью. Они приносят пользу только тогда, когда устраняют значительное количество блоков данных и могут даже ввести накладные расходы, если запрос или структура данных не совпадают. Если даже одно совпадение существует в блоке, весь этот блок все равно нужно прочитать.
Эффективное использование индексов пропуска часто зависит от сильной корреляции между индексируемой колонкой и первичным ключом таблицы или от вставки данных таким образом, чтобы сгруппировать похожие значения вместе.
В общем, индексы пропуска данных лучше всего применять после обеспечения правильного проектирования первичного ключа и оптимизации типов. Они особенно полезны для:
- Колонок с высокой общей кардинальностью, но низкой кардинальностью внутри блока.
- Редких значений, которые критически важны для поиска (например, коды ошибок, конкретные ID).
- Случаев, когда фильтрация происходит по колонкам, не являющимся первичными ключами, с локализованным распределением.
Всегда:
- тестируйте индексы пропуска на реальных данных с реалистичными запросами. Пробуйте разные типы индексов и значения гранулярности.
- Оцените их влияние с помощью инструментов, таких как send_logs_level='trace' и
EXPLAIN indexes=1, чтобы увидеть эффективность индекса. - Всегда оценивайте размер индекса и то, как он зависит от гранулярности. Уменьшение размера гранулярности часто будет улучшать производительность до определенного момента, что приводит к фильтрации большего количества гранул, которые нужно просканировать. Однако, когда размер индекса увеличивается с меньшей гранулярностью, производительность также может ухудшиться. Измеряйте производительность и размер индекса для различных точек данных гранулярности. Это особенно актуально для индексов фильтра Блума.
При правильном использовании индексы пропуска могут обеспечить значительный прирост производительности - при слепом использовании они могут добавить ненужные затраты.
Для более подробного руководства по индексам пропуска данных смотрите здесь.
Пример
Рассмотрим следующую оптимизированную таблицу. Она содержит данные Stack Overflow с одной строкой на пост.
Эта таблица оптимизирована для запросов, которые фильтруют и агрегируют по типу поста и дате. Предположим, мы хотим подсчитать количество постов с более чем 10,000,000 просмотров, опубликованных после 2009 года.
Этот запрос может исключить некоторые строки (и гранулы) с помощью первичного индекса. Однако большинство строк все равно нужно прочитать, как указано в вышеуказанном ответе и следующем EXPLAIN indexes=1:
Простая аналитика показывает, что ViewCount коррелирует с CreationDate (первичным ключом), как можно было бы ожидать - чем дольше пост существует, тем больше времени у него для просмотра.
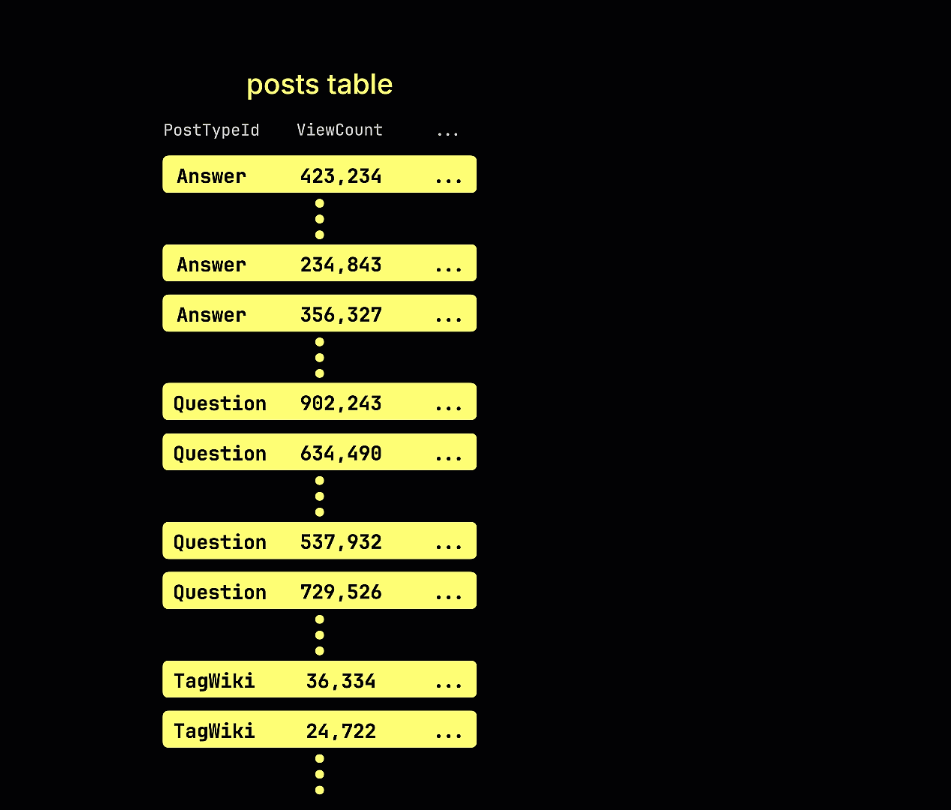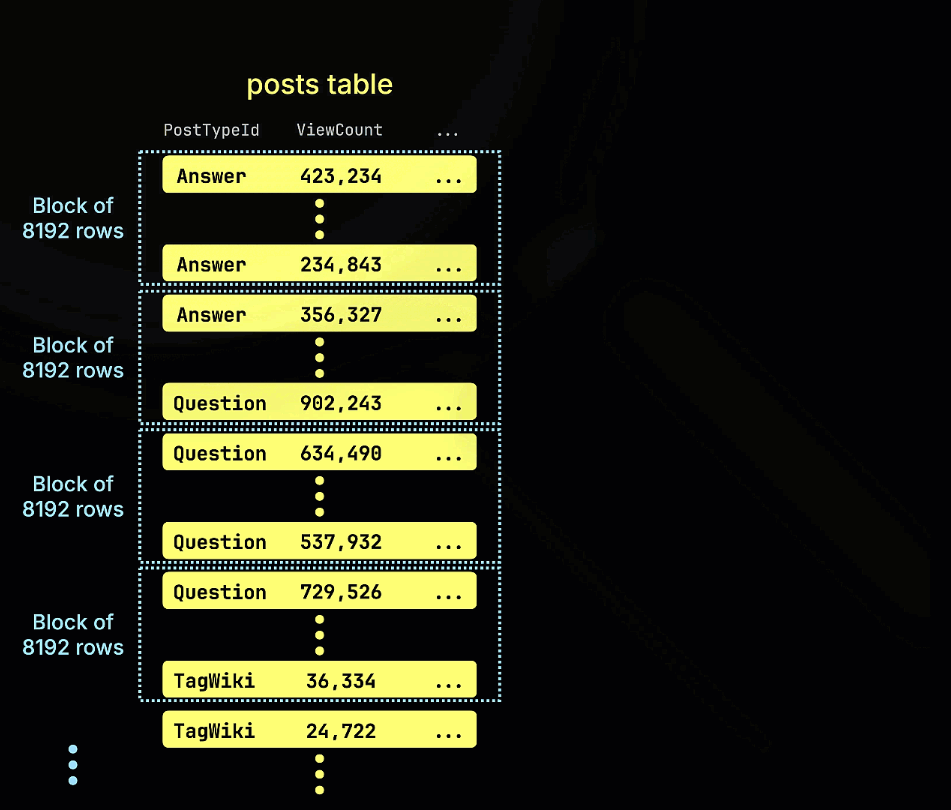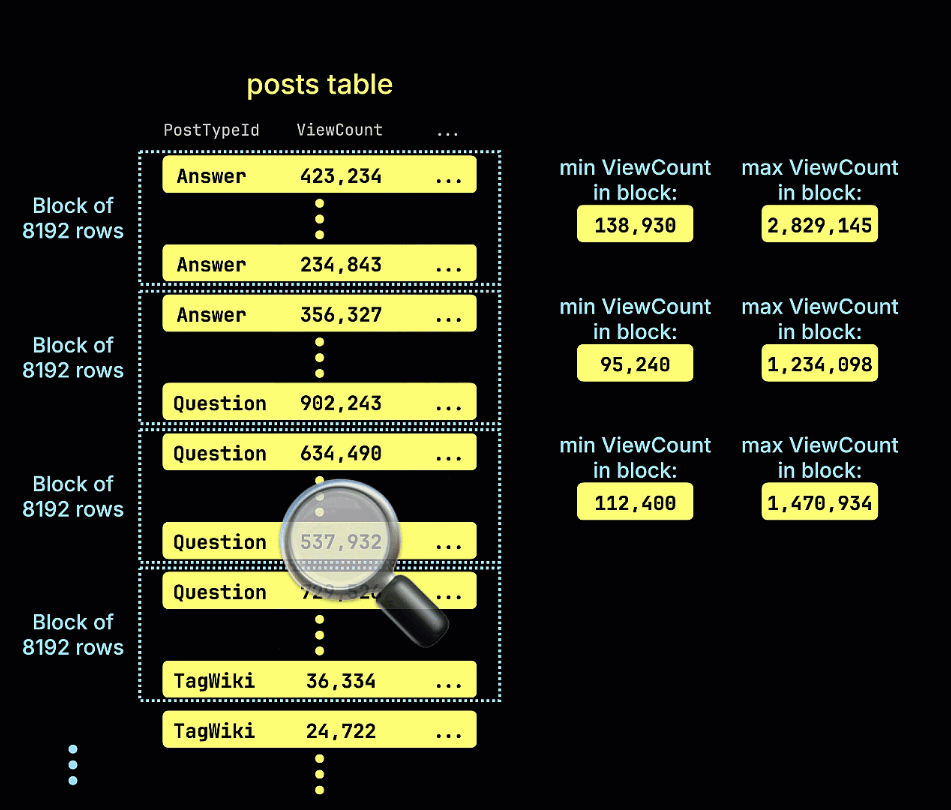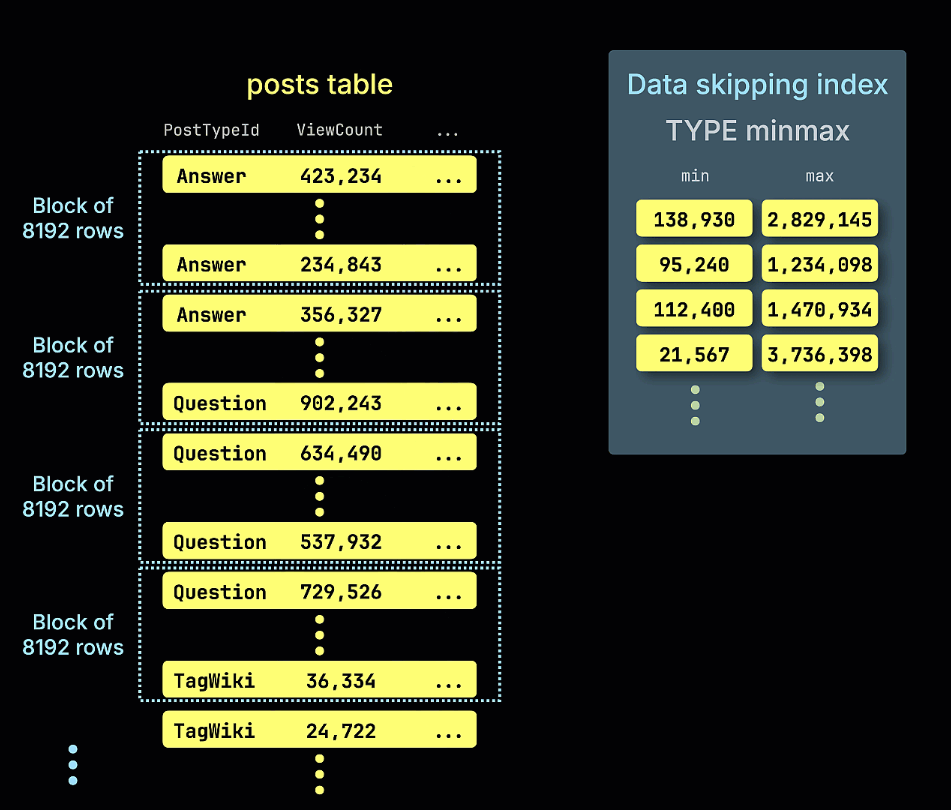
Это делает его логичным выбором для индекса пропуска данных. Учитывая числовой тип, индекс min_max имеет смысл. Мы добавляем индекс с помощью следующих команд ALTER TABLE - сначала добавляем его, затем "материализуем".
Этот индекс также мог быть добавлен во время первоначального создания таблицы. Схема с определенным индексом min max как частью DDL:
Следующая анимация иллюстрирует, как строится наш индекс пропуска minmax для примера таблицы, отслеживая минимальные и максимальные значения ViewCount для каждого блока строк (гранула) в таблице:
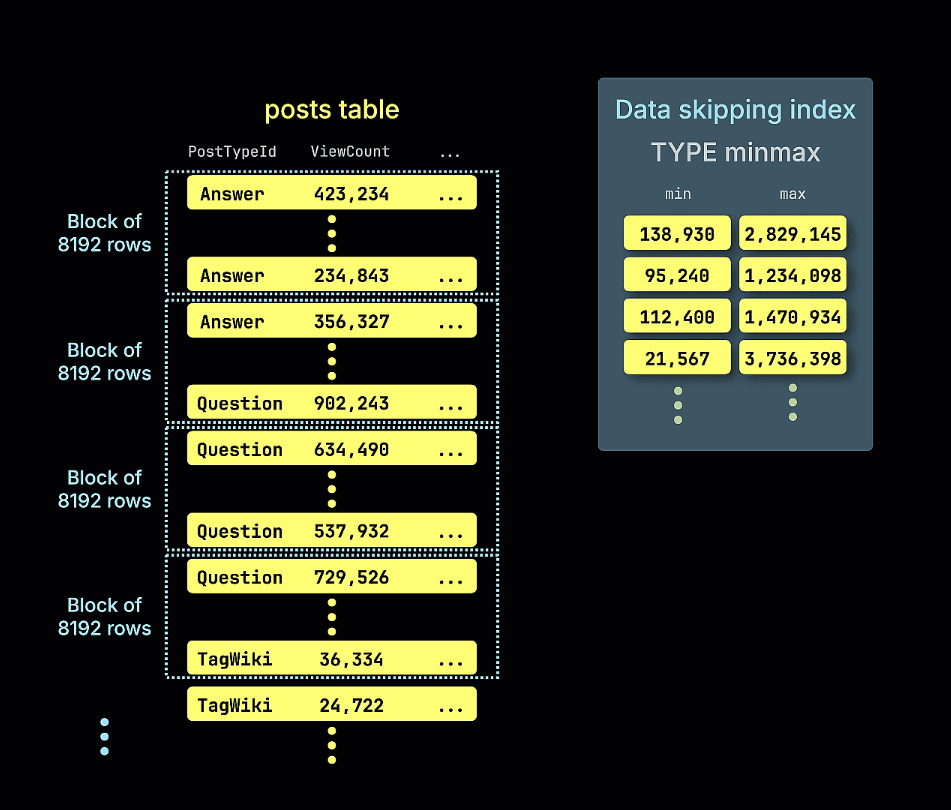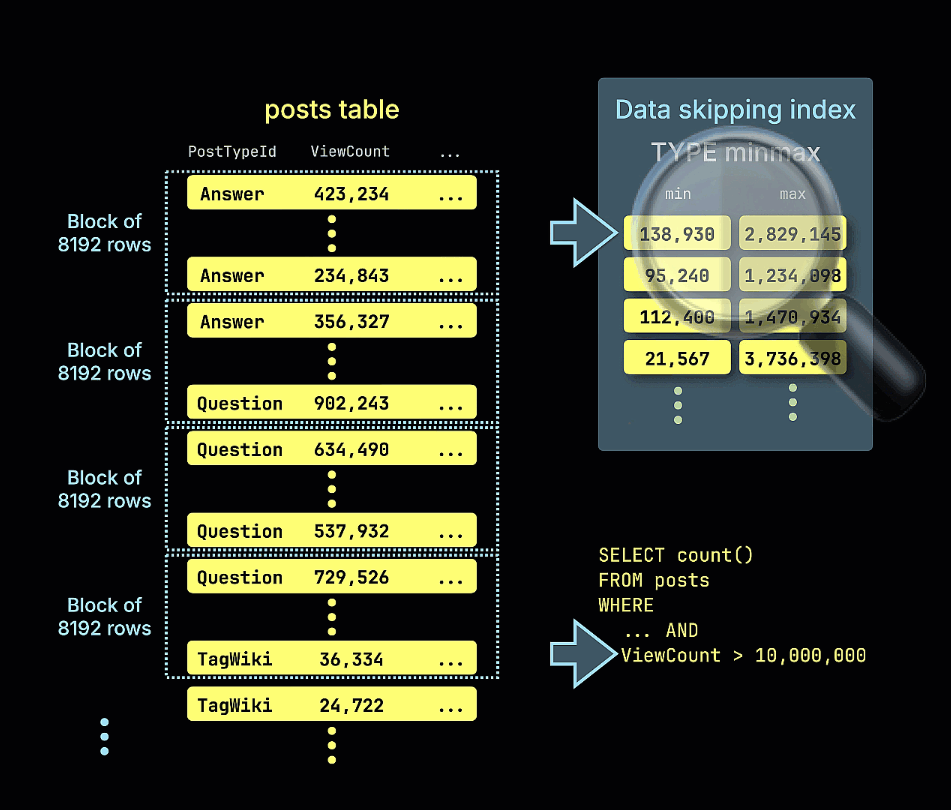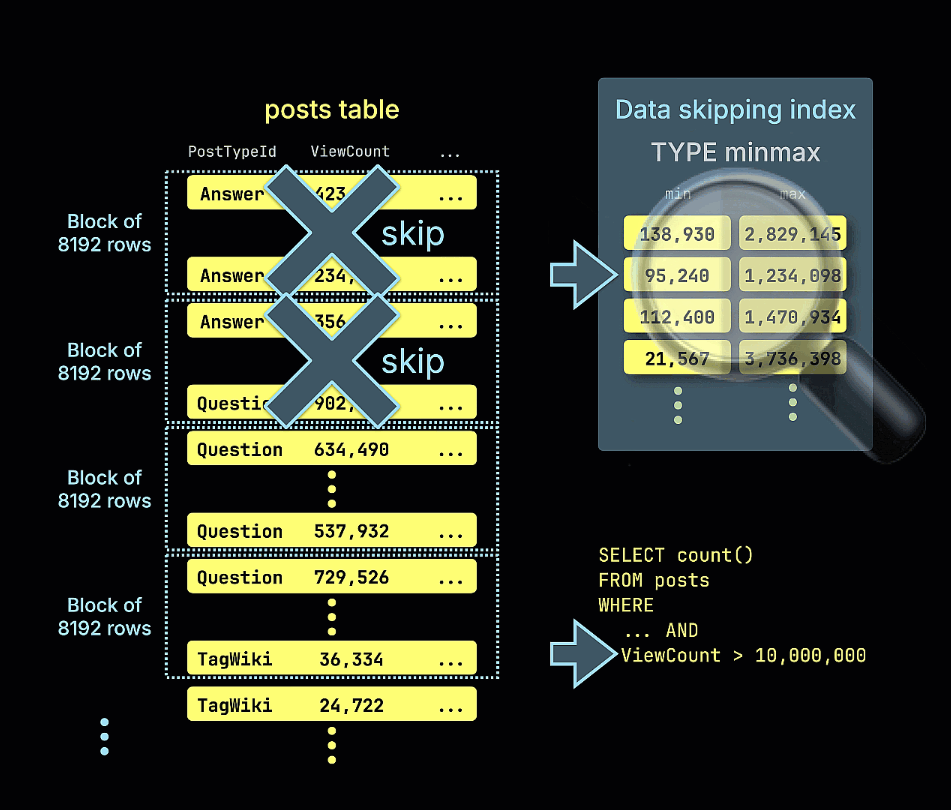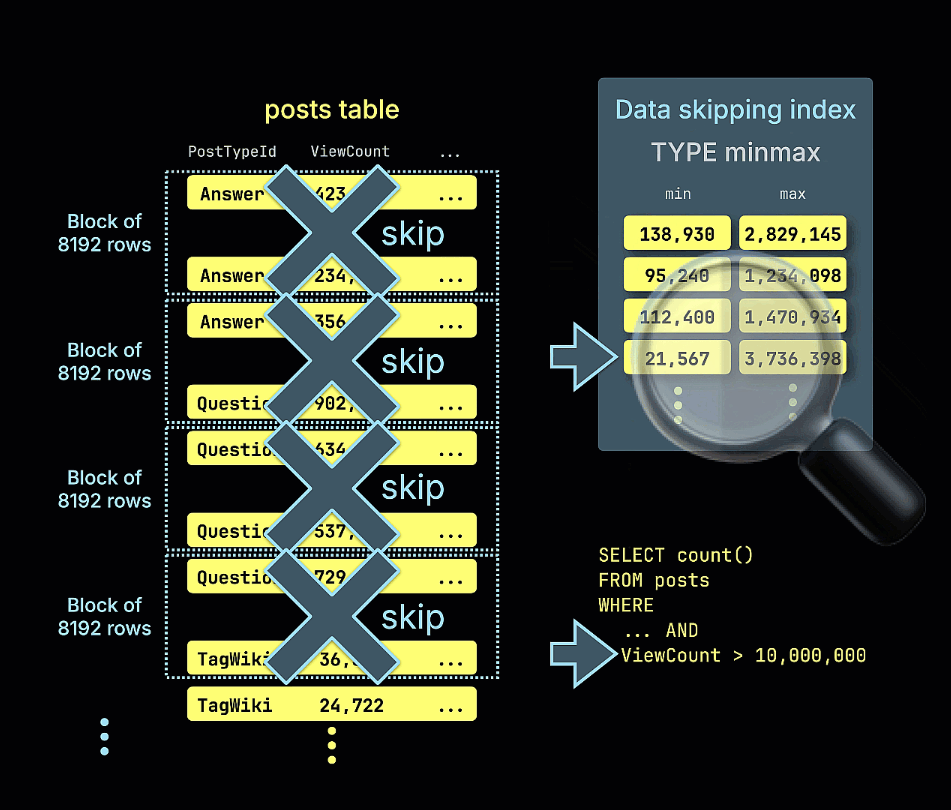
Повторение нашего предыдущего запроса показывает значительные улучшения производительности. Обратите внимание на уменьшенное количество просканированных строк:
Команда EXPLAIN indexes=1 подтверждает использование индекса.
Мы также показываем анимацию, как индекс пропуска minmax отсекает все блоки строк, которые не могут содержать совпадения для предиката ViewCount > 10,000,000 в нашем примере запроса: