Хранилища данных
Что такое разделение вычислений?
Разделение вычислений доступно для уровней Scale и Enterprise.
Каждый сервис ClickHouse Cloud включает:
- Требуется группа из двух или более узлов (или реплик) ClickHouse, но дочерние сервисы могут быть единственной репликой.
- Точка доступа (или несколько точек доступа, созданных через консоль ClickHouse Cloud UI), которая является URL сервиса, который вы используете для подключения к сервису (например,
https://dv2fzne24g.us-east-1.aws.clickhouse.cloud:8443). - Папка объектного хранилища, в которой сервис хранит все данные и частично метаданные:
Дочерние одиночные сервисы могут масштабироваться вертикально, в отличие от одиночных родительских сервисов.
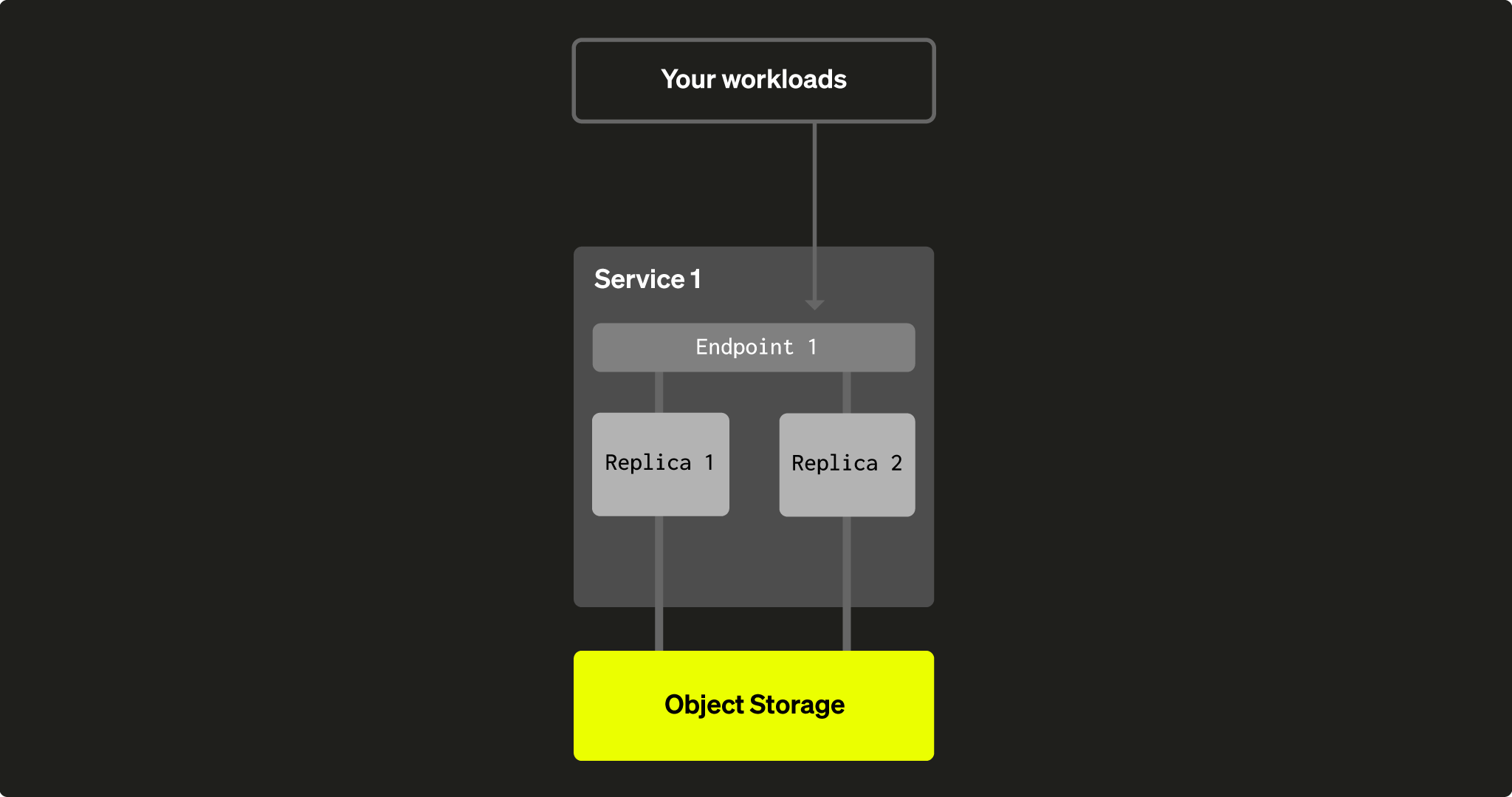
Fig. 1 - текущий сервис в ClickHouse Cloud
Разделение вычислений позволяет пользователям создавать несколько групп узлов вычислений, каждая из которых имеет свою собственную точку доступа и использует одну и ту же папку объектного хранилища, а следовательно, одни и те же таблицы, представления и т. д.
Каждая группа узлов вычислений будет иметь свою собственную точку доступа, поэтому вы можете выбирать, какой набор реплик использовать для ваших рабочих нагрузок. Некоторые из ваших рабочих нагрузок могут быть удовлетворены только одной небольшой репликой, а другим могут потребоваться полная высокая доступность (HA) и сотни гигабайт памяти. Разделение вычислений также позволяет вам отделить операции чтения от операций записи, чтобы они не мешали друг другу:
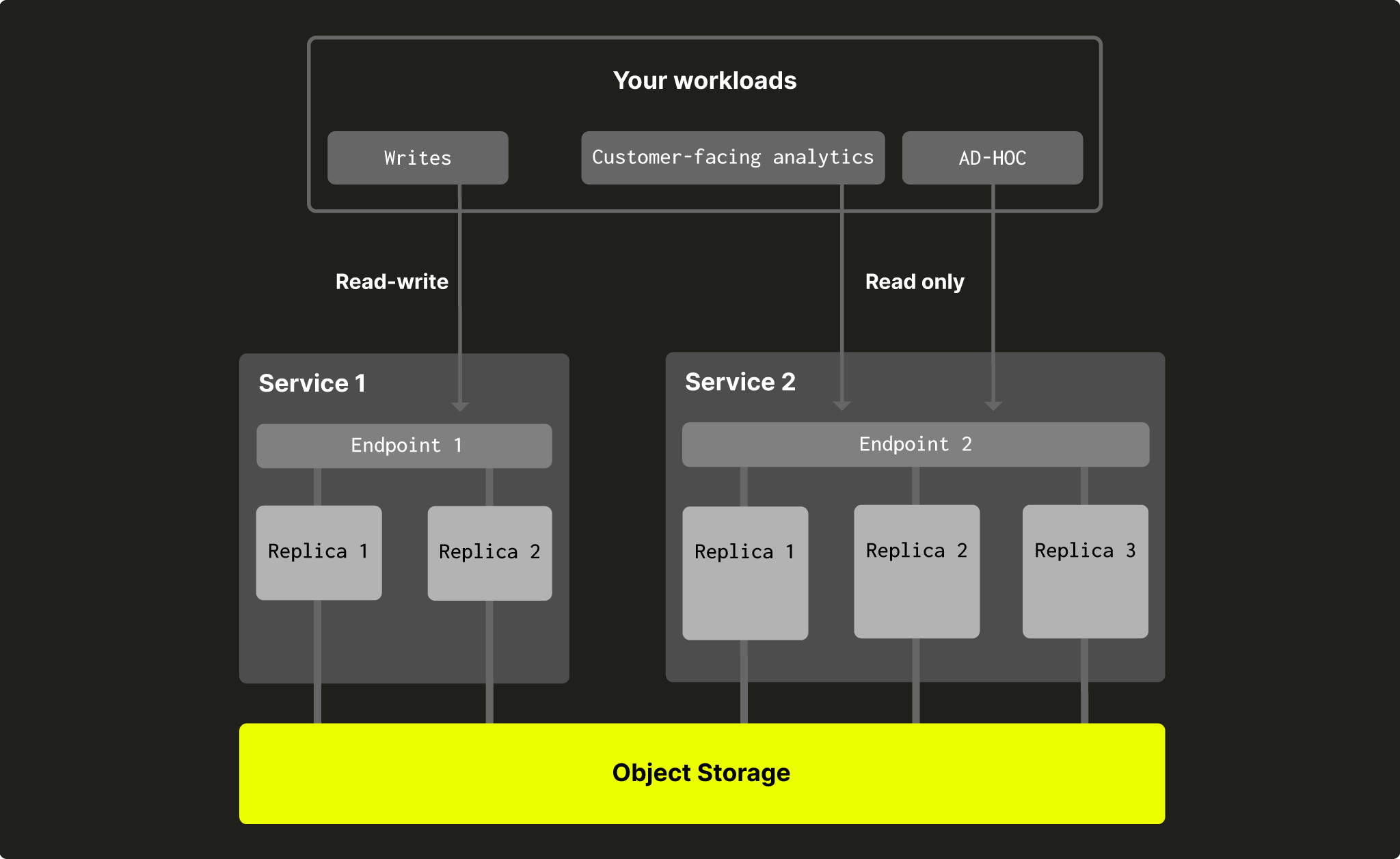
Fig. 2 - разделение вычислений в ClickHouse Cloud
Можно создать дополнительные сервисы, которые будут делиться одними и теми же данными с вашими существующими сервисами, или создать совершенно новую настройку с несколькими сервисами, которые разделяют одни и те же данные.
Что такое склад?
В ClickHouse Cloud склад — это набор сервисов, которые делятся одними и теми же данными. Каждый склад имеет основной сервис (этот сервис был создан первым) и вторичные сервисы. Например, на скриншоте ниже вы можете увидеть склад "DWH Prod" с двумя сервисами:
- Основной сервис
DWH Prod - Вторичный сервис
DWH Prod Subservice

Fig. 3 - Пример склада
Все сервисы в складе делят одно и то же:
- Регион (например, us-east1)
- Провайдер облачных сервисов (AWS, GCP или Azure)
- Версия базы данных ClickHouse
Вы можете сортировать сервисы по складу, к которому они принадлежат.
Контроль доступа
Учетные данные базы данных
Поскольку все в складе делят один и тот же набор таблиц, они также делят контроль доступа к этим другим сервисам. Это означает, что все пользователи базы данных, созданные в Сервисе 1, также смогут использовать Сервис 2 с теми же разрешениями (гранты на таблицы, представления и т. д.) и наоборот. Пользователи будут использовать другую точку доступа для каждого сервиса, но будут использовать одно и то же имя пользователя и пароль. Другими словами, пользователи делятся между сервисами, которые работают с одним и тем же хранилищем:
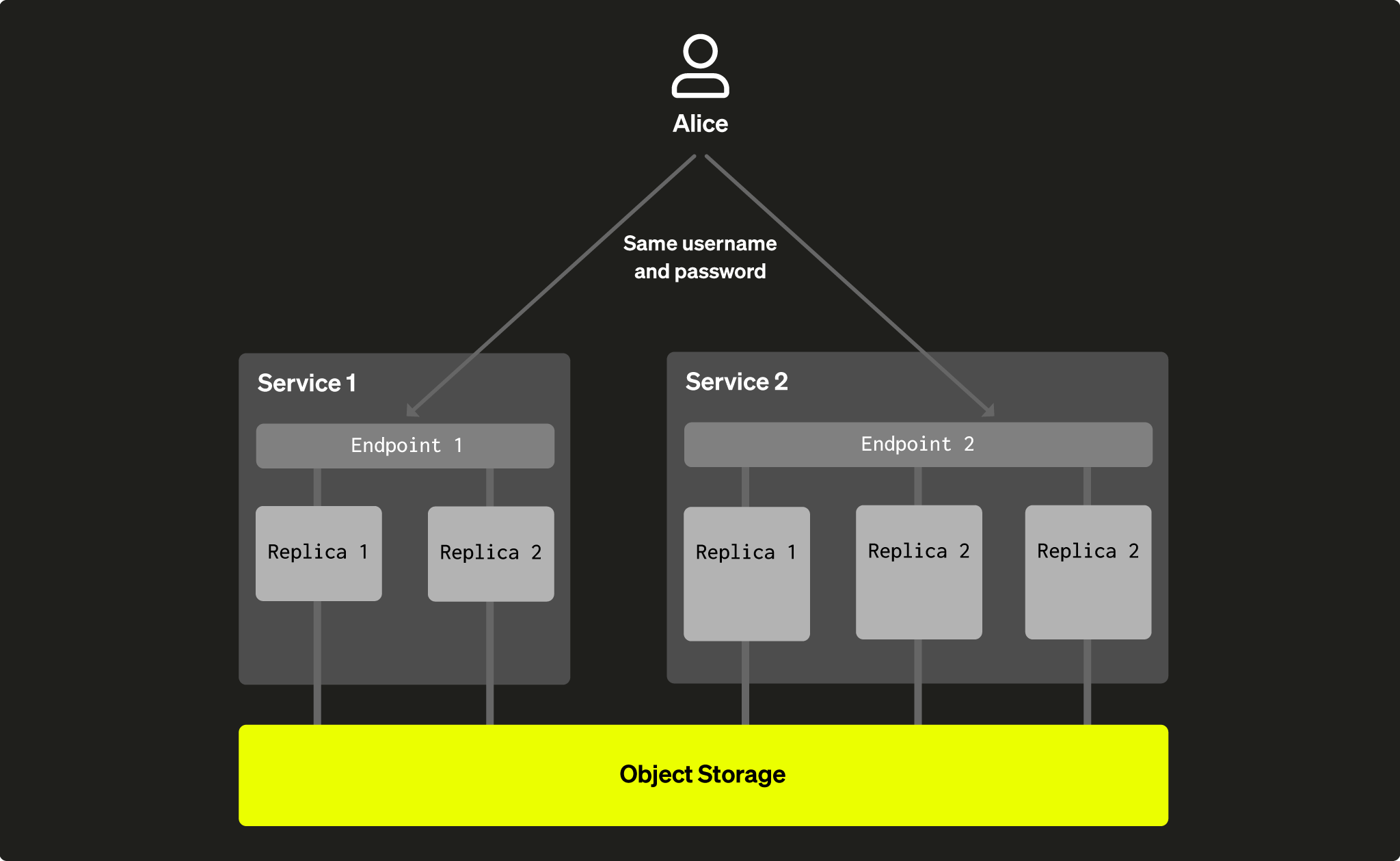
Fig. 4 - пользователь Элис был создан в Сервисе 1, но она может использовать те же учетные данные для доступа ко всем сервисам, которые делят одни и те же данные
Контроль доступа к сети
Часто бывает полезно ограничить доступ к конкретным сервисам для использования другими приложениями или произвольными пользователями. Это можно сделать, используя сетевые ограничения, аналогично тому, как это сейчас настроено для обычных сервисов (перейдите в Настройки на вкладке сервиса в конкретном сервисе в консоли ClickHouse Cloud).
Вы можете применить настройки фильтрации IP отдельно для каждого сервиса, что означает, что вы можете контролировать, какое приложение может получить доступ к какому сервису. Это позволяет вам ограничивать пользователей от использования конкретных сервисов:
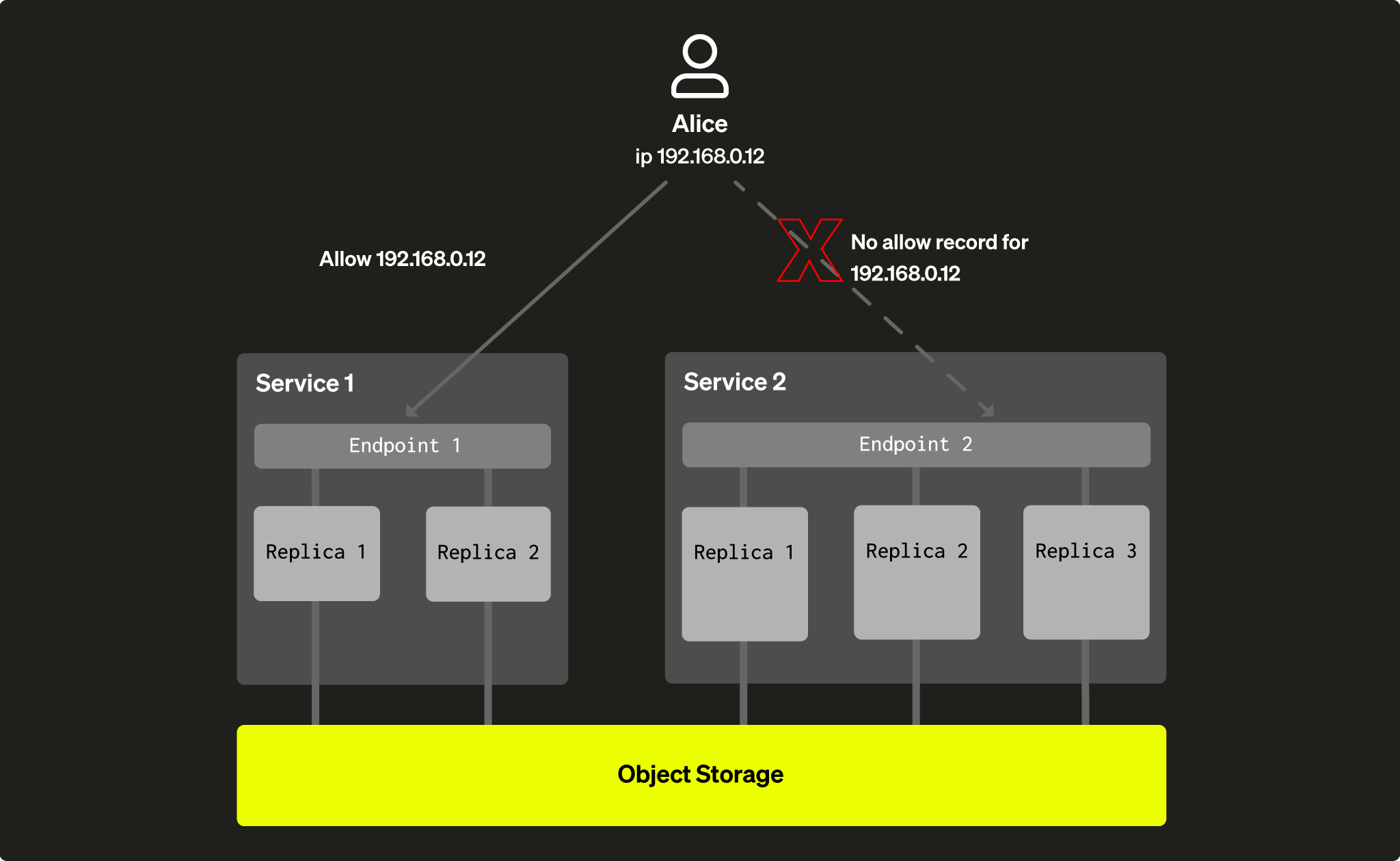
Fig. 5 - Элис ограничена в доступе к Сервису 2 из-за сетевых настроек
Чтение и чтение-запись
Иногда полезно ограничить доступ на запись к конкретному сервису и разрешить записи только подмножеству сервисов в складе. Это можно сделать при создании второго и последующих сервисов (первый сервис всегда должен быть с доступом на чтение-запись):
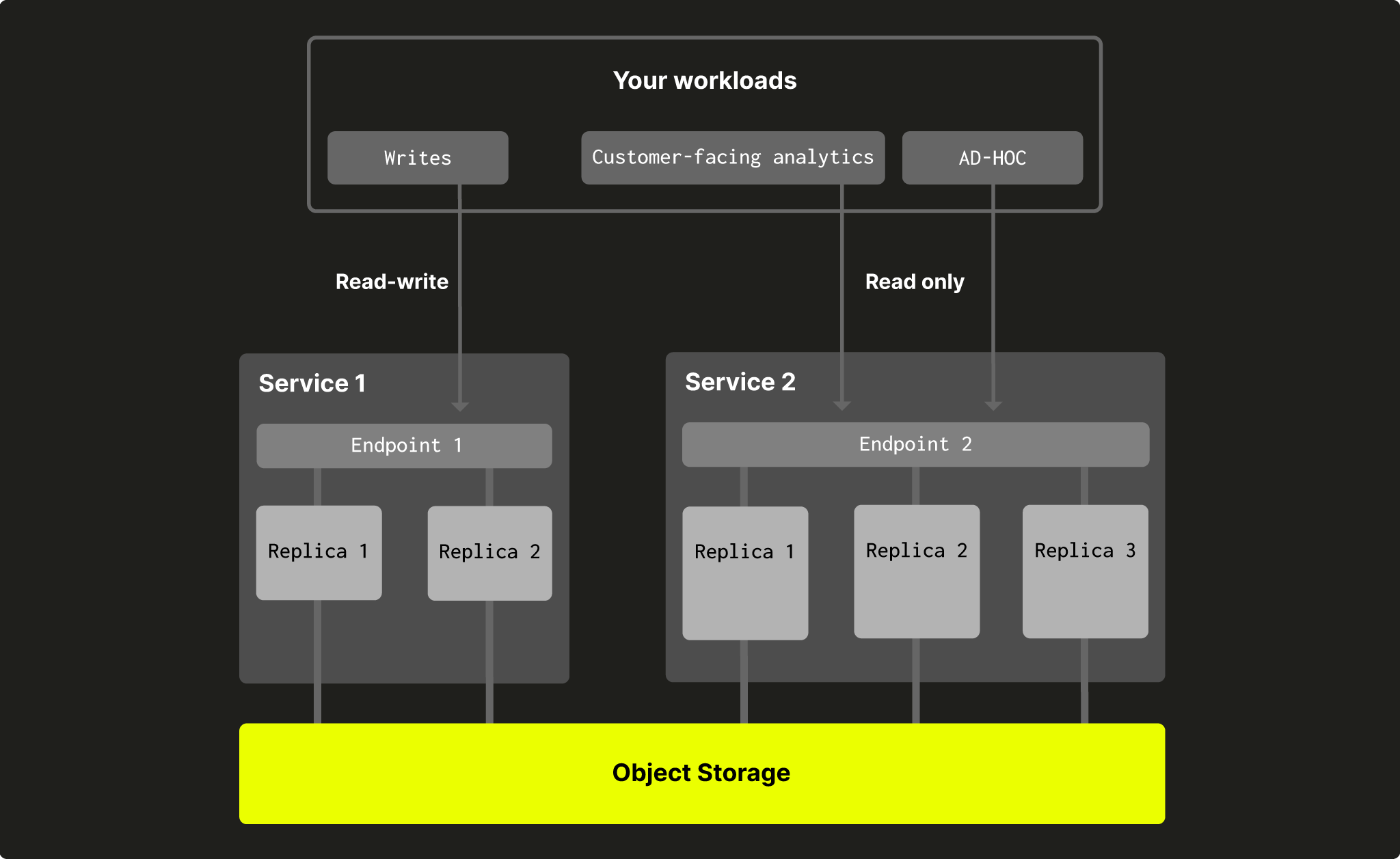
Fig. 6 - Сервисы чтения-записи и только чтения в складе
- Сервисы только для чтения в настоящее время позволяют выполнять операции управления пользователями (создание, удаление и т. д.). Это поведение может измениться в будущем.
- В настоящее время обновляемые материализованные представления выполняются на всех сервисах в складе, включая сервисы только для чтения. Это поведение изменится в будущем, однако, и они будут выполняться только на RW сервисах.
Масштабирование
Каждый сервис в складе можно настроить на вашу рабочую нагрузку в терминах:
- Количество узлов (реплик). Основной сервис (сервис, который был создан первым в складе) должен иметь 2 или более узлов. Каждый вторичный сервис может иметь 1 или более узлов.
- Размер узлов (реплик)
- Должен ли сервис масштабироваться автоматически
- Должен ли сервис быть бездействующим при неактивности (не может быть применимо к первому сервису в группе - смотрите раздел Ограничения)
Изменения в поведении
После включения разделения вычислений для сервиса (была создана как минимум одна вторичная служба), вызов функции clusterAllReplicas() с именем кластера default будет использовать только реплики из сервиса, где она была вызвана. Это означает, что если к одним и тем же данным подключены два сервиса, и от сервиса 1 вызывается clusterAllReplicas(default, system, processes), будут показаны только процессы, работающие на сервисе 1. Если необходимо, вы все равно можете вызвать clusterAllReplicas('all_groups.default', system, processes), например, чтобы получить доступ ко всем репликам.
Ограничения
-
Основной сервис всегда должен быть активен и не должен быть в состоянии бездействия (это ограничение будет снято через некоторое время после GA). Во время частного предпросмотра и некоторое время после GA основной сервис (обычно существующий сервис, который вы хотите расширить, добавив другие сервисы) всегда будет активен, и настройка бездействия будет отключена. Вы не сможете остановить или сделать бездействующим основной сервис, если существует хотя бы одна вторичная служба. После удаления всех вторичных служб вы сможете снова остановить или сделать бездействующим оригинальный сервис.
-
Иногда рабочие нагрузки не могут быть изолированы. Хотя цель состоит в том, чтобы предоставить вам возможность изолировать рабочие нагрузки базы данных друг от друга, могут возникнуть пограничные случаи, когда одна рабочая нагрузка в одном сервисе повлияет на другой сервис, разделяющий одни и те же данные. Это довольно редкие ситуации, которые в основном связаны с рабочими нагрузками, подобными OLTP.
-
Все сервисы с доступом на чтение-запись выполняют фоновые операции слияния. При вставке данных в ClickHouse база данных в первую очередь вставляет данные в некоторые промежуточные партиции, а затем выполняет слияния в фоновом режиме. Эти слияния могут потреблять память и ресурсы CPU. Когда два сервиса с доступом на чтение-запись делят одно и то же хранилище, оба выполняют фоновые операции. Это означает, что может возникнуть ситуация, когда в Сервисе 1 выполняется запрос
INSERT, но операция слияния завершается Сервисом 2. Обратите внимание, что сервисы только для чтения не выполняют фоновые слияния и, следовательно, не тратят свои ресурсы на эту операцию. -
Все сервисы с доступом на чтение-запись выполняют операции вставки для движка таблицы S3Queue. При создании таблицы S3Queue на RW сервисе все остальные RW сервисы в складе могут выполнять чтение данных из S3 и запись данных в базу данных.
-
Вставки в одном сервисе с доступом на чтение-запись могут предотвратить переход другого сервиса с доступом на чтение-запись в состояние бездействия, если бездействие включено. В результате второй сервис выполняет фоновые операции слияния для первого сервиса. Эти фоновые операции могут помешать второму сервису перейти в спящий режим при бездействии. Как только фоновые операции завершены, сервис будет переведен в состояние бездействия. Сервисы только для чтения не подвержены этому и будут переведены в состояние бездействия без задержек.
-
Запросы CREATE/RENAME/DROP DATABASE могут блокироваться бездействующими/остановленными сервисами по умолчанию. Эти запросы могут зависнуть. Чтобы обойти это, вы можете выполнять запросы управления базой данных с
settings distributed_ddl_task_timeout=0на уровне сессии или для отдельных запросов. Например:
-
В очень редких случаях вторичные сервисы, которые находятся в состоянии бездействия или остановлены на долгое время (дни) без пробуждения/запуска, могут вызывать снижение производительности других сервисов в том же складе. Эта проблема будет решена в ближайшее время и связана с мутациями, выполняющимися в фоновом режиме. Если вы думаете, что сталкиваетесь с этой проблемой, пожалуйста, свяжитесь с Поддержкой ClickHouse.
-
В настоящее время существует мягкий лимит на 5 сервисов на склад. Свяжитесь с командой поддержки, если вам нужно больше 5 сервисов в одном складе.
Цены
Цены на вычисления одинаковые для всех сервисов в складе (основного и вторичных). Хранение взимается только один раз - оно включено в первый (оригинальный) сервис.
Пожалуйста, обратитесь к калькулятору цен на странице цены, который поможет оценить стоимость на основе размера вашей рабочей нагрузки и выбора уровня.
Резервные копии
- Поскольку все сервисы в одном складе делят одно и то же хранилище, резервные копии создаются только на основном (начальном) сервисе. Таким образом, данные для всех сервисов в складе резервируются.
- Если вы восстанавливаете резервную копию из основного сервиса склада, она будет восстановлена в совершенно новом сервисе, не связанном с существующим складом. Вы можете сразу добавить больше сервисов в новый сервис сразу после завершения восстановления.
Использование складов
Создание склада
Чтобы создать склад, вам нужно создать второй сервис, который будет делиться данными с существующим сервисом. Это можно сделать, нажав на знак плюс на любом из существующих сервисов:
Fig. 7 - Нажмите на знак плюс, чтобы создать новый сервис в складе
На экране создания сервиса первоначальный сервис будет выбран в выпадающем списке в качестве источника для данных нового сервиса. После создания эти два сервиса образуют склад.
Переименование склада
Существует два способа переименовать склад:
- Вы можете выбрать "Сортировать по складу" на странице сервисов в правом верхнем углу, а затем нажать на значок карандаша рядом с именем склада;
- Вы можете нажать на имя склада в любом из сервисов и переименовать склад там.
Удаление склада
Удаление склада означает удаление всех вычислительных сервисов и данных (таблиц, представлений, пользователей и т. д.). Это действие нельзя отменить. Вы можете удалить склад только путем удаления первого созданного сервиса. Для этого:
- Удалите все сервисы, созданные в дополнение к первому создаваемому сервису;
- Удалите первый сервис (внимание: все данные склада будут удалены на этом этапе).
