Стратегии дедупликации (с использованием CDC)
Обновления и удаления, реплицируемые из Postgres в ClickHouse, приводят к дублированию строк в ClickHouse из-за его структуры хранения данных и процесса репликации. Эта страница описывает, почему это происходит, и стратегии, которые можно использовать в ClickHouse для обработки дубликатов.
Как данные реплицируются?
Логическое декодирование PostgreSQL
ClickPipes использует Логическое декодирование Postgres для получения изменений по мере их появления в Postgres. Процесс Логического декодирования в Postgres позволяет таким клиентам, как ClickPipes, получать изменения в удобочитаемом формате, т.е. в виде серии INSERT, UPDATE и DELETE.
ReplacingMergeTree
ClickPipes сопоставляет таблицы Postgres с ClickHouse, используя движок ReplacingMergeTree. ClickHouse показывает наилучшие результаты при работе с нагрузками только на добавление и не рекомендует частые UPDATE. В этом случае ReplacingMergeTree особенно мощен.
С помощью ReplacingMergeTree обновления моделируются как вставки с новой версией (_peerdb_version) строки, в то время как удаления представляют собой вставки с новой версией и _peerdb_is_deleted, установленным в true. Движок ReplacingMergeTree дедуплицирует/сливает данные в фоновом режиме и сохраняет последнюю версию строки для данного первичного ключа (id), что позволяет эффективно обрабатывать UPDATE и DELETE как версионные вставки.
Ниже приведен пример оператора CREATE TABLE, выполняемого ClickPipes для создания таблицы в ClickHouse.
Иллюстративный пример
На иллюстрации ниже показан базовый пример синхронизации таблицы users между PostgreSQL и ClickHouse с использованием ClickPipes.
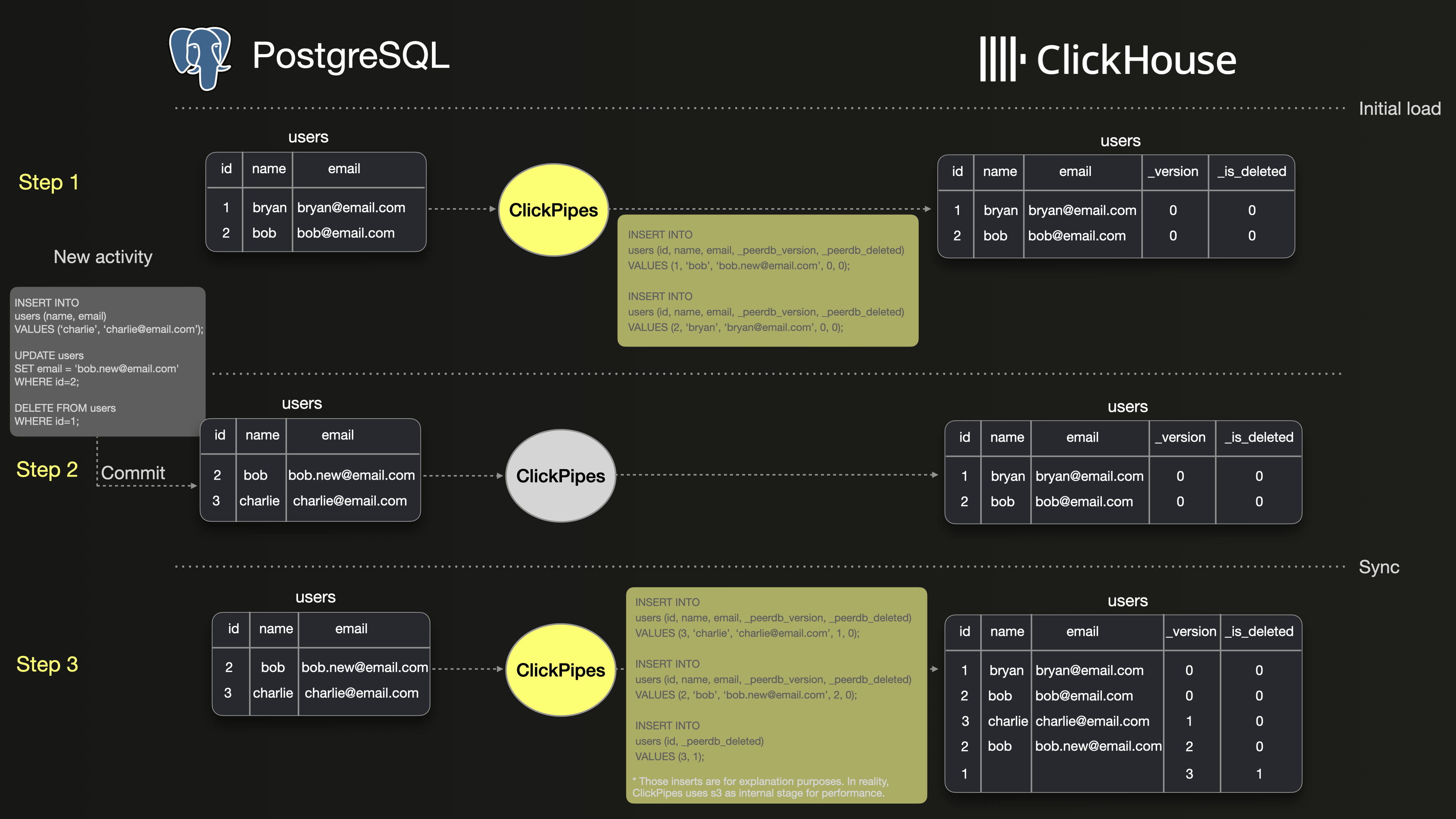
Шаг 1 показывает начальный снимок из 2 строк в PostgreSQL и ClickPipes, выполняющего начальную загрузку этих 2 строк в ClickHouse. Как вы можете видеть, обе строки копируются в ClickHouse без изменений.
Шаг 2 показывает три операции над таблицей users: вставка новой строки, обновление существующей строки и удаление другой строки.
Шаг 3 показывает, как ClickPipes реплицирует операции INSERT, UPDATE и DELETE в ClickHouse в виде версионных вставок. UPDATE появляется как новая версия строки с ID 2, в то время как DELETE появляется как новая версия ID 1, которая помечена как true с помощью _is_deleted. Из-за этого ClickHouse имеет три дополнительных строки по сравнению с PostgreSQL.
В результате выполнение простого запроса, такого как SELECT count(*) FROM users;, может привести к различным результатам в ClickHouse и PostgreSQL. Согласно документации по слиянию ClickHouse, устаревшие версии строк в конечном итоге отбрасываются в процессе слияния. Однако время выполнения этого слияния непредсказуемо, что означает, что запросы в ClickHouse могут возвращать непоследовательные результаты до его выполнения.
Как мы можем обеспечить идентичные результаты запросов как в ClickHouse, так и в PostgreSQL?
Дедупликация с использованием ключевого слова FINAL
Рекомендуемый способ дедупликации данных в запросах ClickHouse — использовать модификатор FINAL. Это гарантирует, что возвращаются только дедуплицированные строки.
Давайте посмотрим, как применить его к трем различным запросам.
Обратите внимание на условие WHERE в следующих запросах, используемое для фильтрации удаленных строк.
- Простой запрос для подсчета: Подсчитать количество постов.
Это самый простой запрос, который вы можете выполнить, чтобы проверить, правильно ли прошла синхронизация. Оба запроса должны возвращать одинаковое количество.
- Простая агрегация с JOIN: Топ 10 пользователей, которые накопили наибольшее количество просмотров.
Пример агрегации по одной таблице. Наличие дубликатов здесь сильно повлияло бы на результат функции суммы.
Настройка FINAL
Вместо того чтобы добавлять модификатор FINAL к каждому имени таблицы в запросе, вы можете использовать настройку FINAL, чтобы применить ее автоматически ко всем таблицам в запросе.
Эта настройка может применяться как к запросу, так и ко всей сессии.
Политика ROW
Легкий способ скрыть избыточный фильтр _peerdb_is_deleted = 0 — использовать политику ROW. Ниже приведен пример, создающий политику строки для исключения удаленных строк из всех запросов к таблице votes.
Политики строк применяются к списку пользователей и ролей. В этом примере она применяется ко всем пользователям и ролям. Это можно настроить только для конкретных пользователей или ролей.
Запросы как в Postgres
Миграция аналитического набора данных из PostgreSQL в ClickHouse часто требует модификации запросов приложения, чтобы учесть различия в обработке данных и выполнении запросов.
В этом разделе будут рассмотрены методы дедупликации данных при сохранении исходных запросов без изменений.
Представления
Представления — отличный способ скрыть ключевое слово FINAL от запроса, поскольку они не хранят никаких данных и просто выполняют чтение из другой таблицы при каждом доступе.
Ниже приведен пример создания представлений для каждой таблицы нашей базы данных в ClickHouse с ключевым словом FINAL и фильтром для удаленных строк.
Затем мы можем запрашивать представления, используя такой же запрос, какой мы использовали бы в PostgreSQL.
Обновляемое материализованное представление
Другой подход — использовать обновляемое материализованное представление, которое позволяет планировать выполнение запросов для дедупликации строк и хранения результатов в целевой таблице. При каждом запланированном обновлении целевая таблица заменяется на последние результаты запроса.
Ключевое преимущество этого метода заключается в том, что запрос, использующий ключевое слово FINAL, выполняется только один раз во время обновления, что устраняет необходимость в последующих запросах к целевой таблице с использованием FINAL.
Однако недостатком является то, что данные в целевой таблице актуальны только на момент последнего обновления. Тем не менее, для многих случаев использования интервалы обновления от нескольких минут до нескольких часов могут быть достаточными.
Затем вы можете обычным образом запрашивать таблицу deduplicated_posts.
