JDBC коннектор
Этот коннектор следует использовать только в случае, если ваши данные просты и состоят из примитивных типов данных, например, int. Специфичные для ClickHouse типы, такие как maps, не поддерживаются.
В наших примерах мы используем дистрибутив Confluent для Kafka Connect.
Ниже мы описываем простую установку, получение сообщений из одной Kafka темы и вставку строк в таблицу ClickHouse. Мы рекомендуем Confluent Cloud, который предлагает щедрый бесплатный тариф для тех, у кого нет окружения Kafka.
Обратите внимание, что для коннектора JDBC требуется схема (вы не можете использовать обычный JSON или CSV с коннектором JDBC). Хотя схема может быть закодирована в каждом сообщении, то категорически рекомендуется использовать схему Confluent для избегания сопутствующих накладных расходов. Предоставляемый скрипт вставки автоматически извлекает схему из сообщений и вставляет её в реестр - этот скрипт можно повторно использовать для других наборов данных. Предполагается, что ключи Kafka являются строками. Дополнительные детали о схемах Kafka можно найти здесь.
Лицензия
Коннектор JDBC распространяется под Confluent Community License.
Шаги
Соберите ваши данные для подключения
Чтобы подключиться к ClickHouse с помощью HTTP(S), вам необходима следующая информация:
-
ХОСТ и ПОРТ: как правило, порт 8443 при использовании TLS или 8123 при отсутствии TLS.
-
ИМЯ БАЗЫ ДАННЫХ: по умолчанию существует база данных с именем
default, используйте имя базы данных, к которой вы хотите подключиться. -
ИМЯ ПОЛЬЗОВАТЕЛЯ и ПАРОЛЬ: по умолчанию имя пользователя
default. Используйте имя пользователя, подходящее для вашего случая.
Данные для вашего сервиса ClickHouse Cloud доступны в консоли ClickHouse Cloud. Выберите сервис, к которому вы хотите подключиться, и нажмите Подключиться:
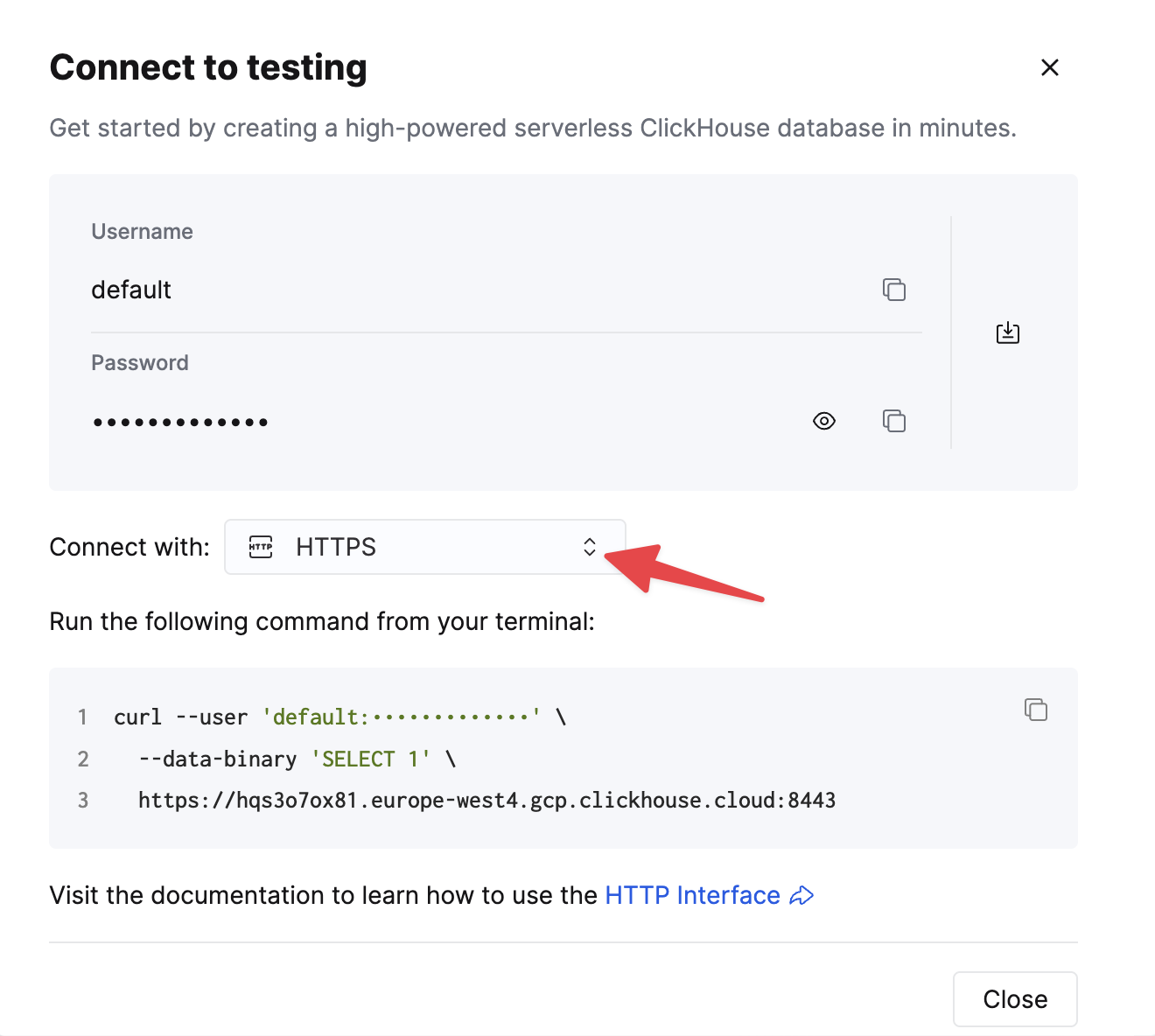
Выберите HTTPS, и данные будут доступны в примере команды curl.
Если вы используете самоуправляемый ClickHouse, детали подключения устанавливаются вашим администратором ClickHouse.
1. Установите Kafka Connect и коннектор
Предполагается, что вы скачали пакет Confluent и установили его локально. Следуйте инструкциям по установке коннектора, которые зафиксированы здесь.
Если вы используете метод установки через confluent-hub, ваши локальные файлы конфигурации будут обновлены.
Для отправки данных в ClickHouse из Kafka мы используем компонент Sink коннектора.
2. Скачайте и установите JDBC драйвер
Скачайте и установите JDBC драйвер ClickHouse clickhouse-jdbc-<version>-shaded.jar отсюда. Установите его в Kafka Connect в соответствии с деталями здесь. Другие драйверы могут работать, но не были протестированы.
Общая проблема: документация рекомендует копировать jar в share/java/kafka-connect-jdbc/. Если у вас возникли проблемы с обнаружением драйвера Connect, скопируйте драйвер в share/confluent-hub-components/confluentinc-kafka-connect-jdbc/lib/. Или измените plugin.path, чтобы включить драйвер - см. ниже.
3. Подготовьте конфигурацию
Следуйте этим инструкциям для настройки Connect в соответствии с типом вашей установки, отметив различия между самостоятельным и распределенным кластером. Если вы используете Confluent Cloud, уместна распределенная настройка.
Следующие параметры имеют значение для использования коннектора JDBC с ClickHouse. Полный список параметров можно найти здесь:
_connection.url_- должно быть в форматеjdbc:clickhouse://<clickhouse хост>:<clickhouse http порт>/<целевой база данных>connection.user- пользователь с правами на запись в целевую базу данныхtable.name.format- таблица ClickHouse для вставки данных. Эта таблица должна существовать.batch.size- количество строк, отправляемых в одном пакете. Убедитесь, что это значение установлено на подходящее большое число. В соответствии с рекомендациями ClickHouse значение 1000 должно рассматриваться как минимум.tasks.max- Коннектор JDBC Sink поддерживает выполнение одной или нескольких задач. Это можно использовать для увеличения производительности. Вместе с размером пакета это ваш основной способ повышения производительности.value.converter.schemas.enable- Установите в false, если используете реестр схем, true, если встраиваете схемы в сообщения.value.converter- Установите в соответствии с вашим типом данных, например, для JSONio.confluent.connect.json.JsonSchemaConverter.key.converter- Установите вorg.apache.kafka.connect.storage.StringConverter. Мы используем строковые ключи.pk.mode- Не актуально для ClickHouse. Установите в none.auto.create- Не поддерживается и должно быть false.auto.evolve- Мы рекомендуем установить false для этой настройки, хотя она может быть поддержана в будущем.insert.mode- Установите в "insert". Другие режимы в данный момент не поддерживаются.key.converter- Установите в соответствии с типами ваших ключей.value.converter- Установите на основе типа данных в вашей теме. Эти данные должны иметь поддерживаемую схему - JSON, Avro или Protobuf форматы.
Если вы используете наш образец данных для тестирования, убедитесь, что следующие параметры установлены:
value.converter.schemas.enable- Установите в false, так как мы используем реестр схем. Установите в true, если встраиваете схему в каждое сообщение.key.converter- Установите в "org.apache.kafka.connect.storage.StringConverter". Мы используем строковые ключи.value.converter- Установите "io.confluent.connect.json.JsonSchemaConverter".value.converter.schema.registry.url- Установите на URL сервера схемы вместе с учетными данными для сервера схемы через параметрvalue.converter.schema.registry.basic.auth.user.info.
Примеры файлов конфигурации для образца данных с Github можно найти здесь, если Connect запускается в режиме самостоятельного выполнения, а Kafka размещен в Confluent Cloud.
4. Создайте таблицу ClickHouse
Убедитесь, что таблица создана, удалив её, если она уже существует из предыдущих примеров. Пример, совместимый с уменьшенным набором данных Github, показан ниже. Обратите внимание на отсутствие любых типов Array или Map, которые в данный момент не поддерживаются:
5. Запустите Kafka Connect
Запустите Kafka Connect в режиме самостоятельного выполнения или распределенного режима.
6. Добавьте данные в Kafka
Вставьте сообщения в Kafka, используя скрипт и конфигурацию, которые предоставлены. Вам нужно будет модифицировать github.config, чтобы включить ваши учетные данные Kafka. Скрипт в данный момент настроен для использования с Confluent Cloud.
Этот скрипт можно использовать для вставки любого ndjson файла в тему Kafka. Он попытается автоматически извлечь схему для вас. Пример конфигурации, предоставленный, будет вставлять только 10k сообщений - измените здесь, если это необходимо. Эта конфигурация также убирает любые несовместимые поля Array из набора данных при вставке в Kafka.
Это необходимо для того, чтобы коннектор JDBC мог преобразовывать сообщения в операторы INSERT. Если вы используете свои данные, убедитесь, что вы либо вставляете схему с каждым сообщением (устанавливая _value.converter.schemas.enable _в true), либо ваши клиенты публикуют сообщения, ссылаясь на схему в реестре.
Kafka Connect должен начать потреблять сообщения и вставлять строки в ClickHouse. Обратите внимание, что предупреждения, касающиеся "[JDBC Compliant Mode] Транзакция не поддерживается.", ожидаемы и могут быть проигнорированы.
Простое чтение из целевой таблицы "Github" должно подтвердить вставку данных.
Рекомендуемое дальнейшее чтение
- Параметры конфигурации Sink Kafka
- Глубокое погружение в Kafka Connect – JDBC Source Connector
- Глубокое погружение в Kafka Connect JDBC Sink: Работа с первичными ключами
- Kafka Connect в действии: JDBC Sink - для тех, кто предпочитает смотреть, а не читать.
- Глубокое погружение в Kafka Connect – Конвертеры и сериализация объяснены
