Слияния частей
Что такое слияния частей в ClickHouse?
ClickHouse быстрый не только для запросов, но и для вставок, благодаря своему слою хранения, который работает аналогично деревьям LSM:
① Вставки (в таблицы из семейства MergeTree engine) создают отсортированные, неизменяемые части данных.
② Вся обработка данных перегружена на фоновое слияние частей.
Это делает записи данных легковесными и высокоэффективными.
Чтобы контролировать количество ^^частей^^ на таблицу и реализовать ② выше, ClickHouse непрерывно сливает (по партициям) меньшие ^^части^^ в большие в фоновом режиме, пока они не достигнут сжатого размера примерно ~150 ГБ.
Следующая диаграмма иллюстрирует процесс фонового слияния:
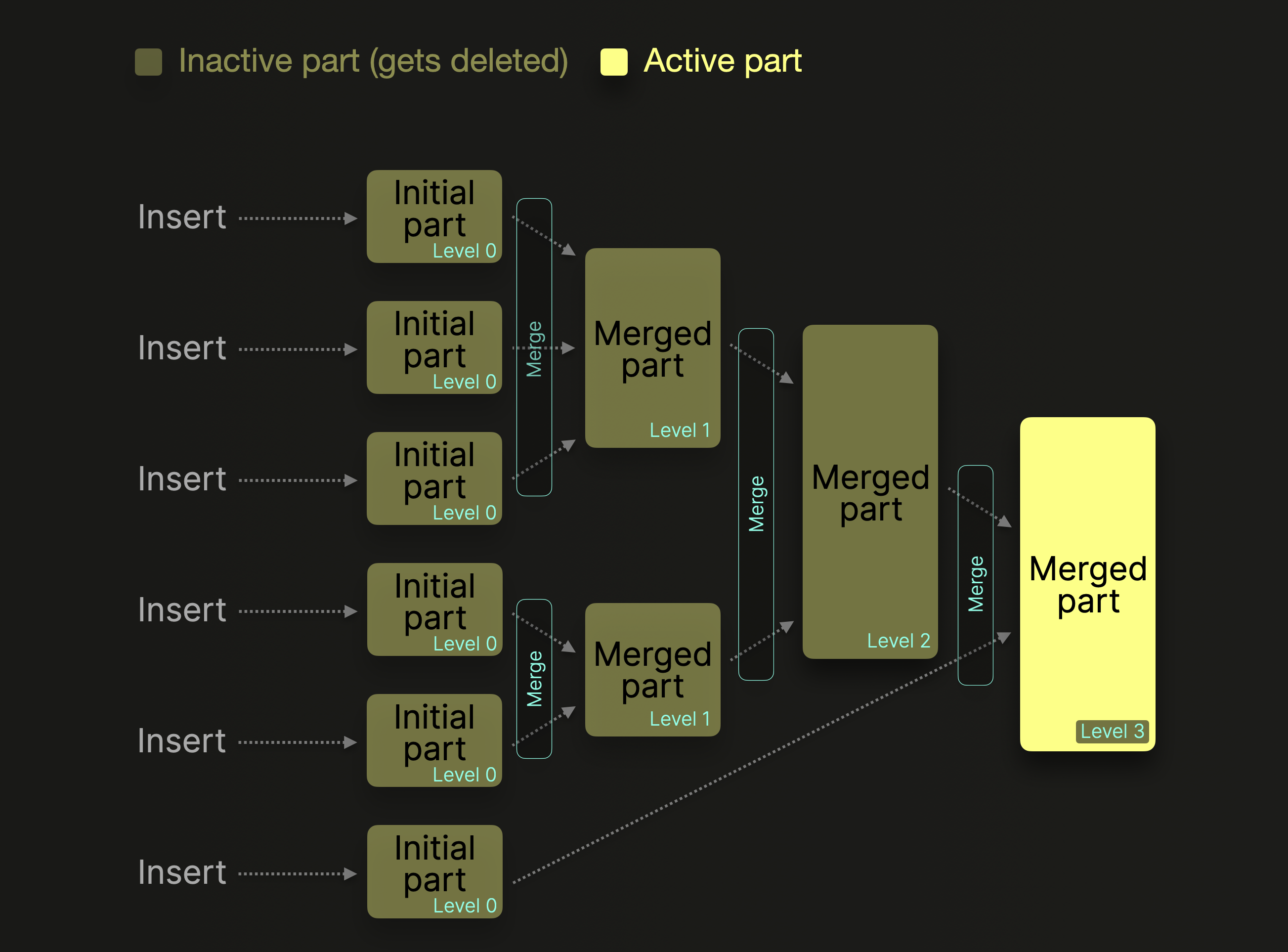
merge level части увеличивается на один с каждым дополнительным слиянием. Уровень 0 означает, что часть новая и еще не была слита. ^^Части^^, которые были слиты в большие ^^части^^, помечаются как неактивные и в конечном счете удаляются после настраиваемого времени (по умолчанию 8 минут). Со временем это создает дерево слитых ^^частей^^. Отсюда и название merge tree таблицы.
Мониторинг слияний
В примере что такое части таблицы мы показали, что ClickHouse отслеживает все части таблицы в системной таблице parts. Мы использовали следующий запрос для получения уровня слияния и количества сохраненных строк на каждую активную часть таблицы примера:
Результат ранее задокументированного запроса показывает, что у таблицы примера было четыре активные ^^части^^, каждая из которых была создана в результате одного слияния первоначально вставленных ^^частей^^:
[Запуск] (https://sql.clickhouse.com/?query=U0VMRUNUCiAgICBuYW1lLAogICAgbGV2ZWwsCiAgICByb3dzCkZST00gc3lzdGVtLnBhcnRzCldIRVJFIChkYXRhYmFzZSA9ICd1aycpIEFORCAoYHRhYmxlYCA9ICd1a19wcmljZV9wYWlkX3NpbXBsZScpIEFORCBhY3RpdmUKT1JERVIgQlkgbmFtZSBBU0M7&run_query=true&tab=results) теперь показывает, что четыре ^^части^^ слились в одну финальную часть (если только в таблицу не было новых вставок):
В ClickHouse 24.10 была добавлена новая панель мониторинга слияний в встроенные панели мониторинга. Доступная как в OSS, так и в облаке через HTTP-обработчик /merges, мы можем использовать ее для визуализации всех слияний частей для нашей таблицы примера:
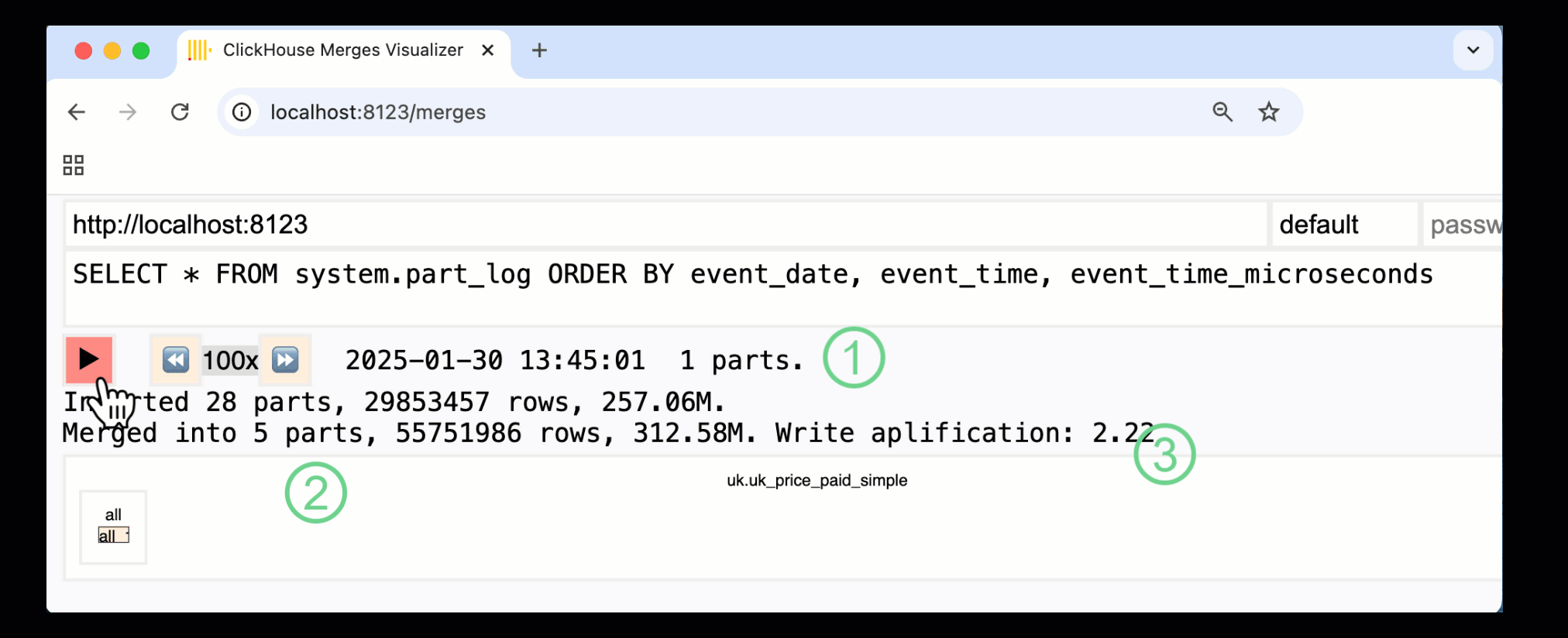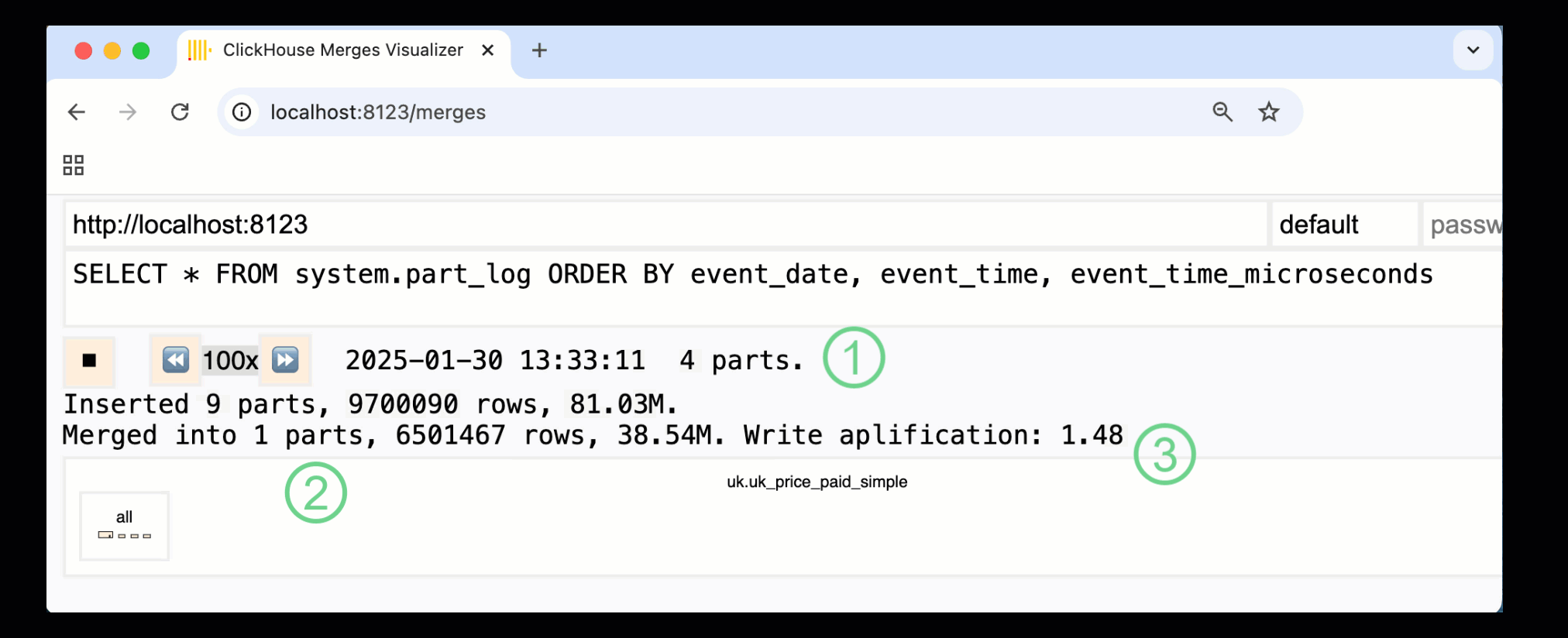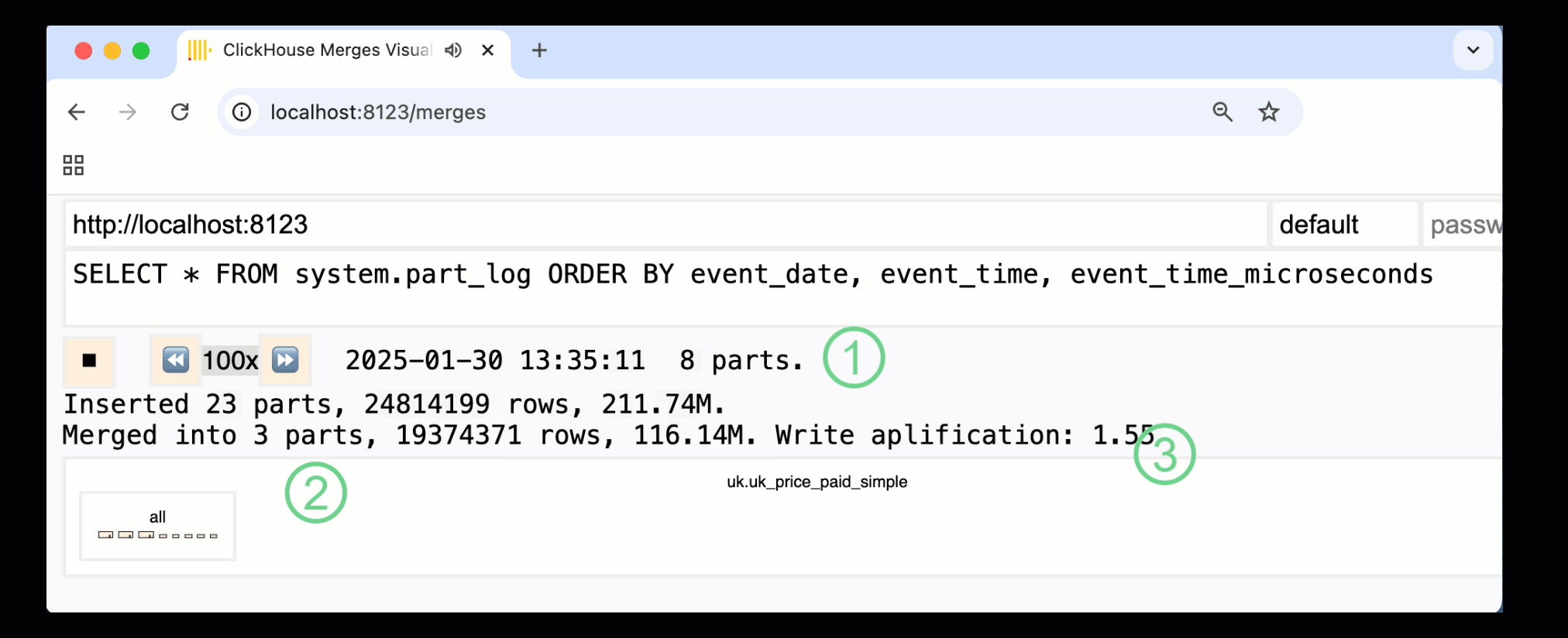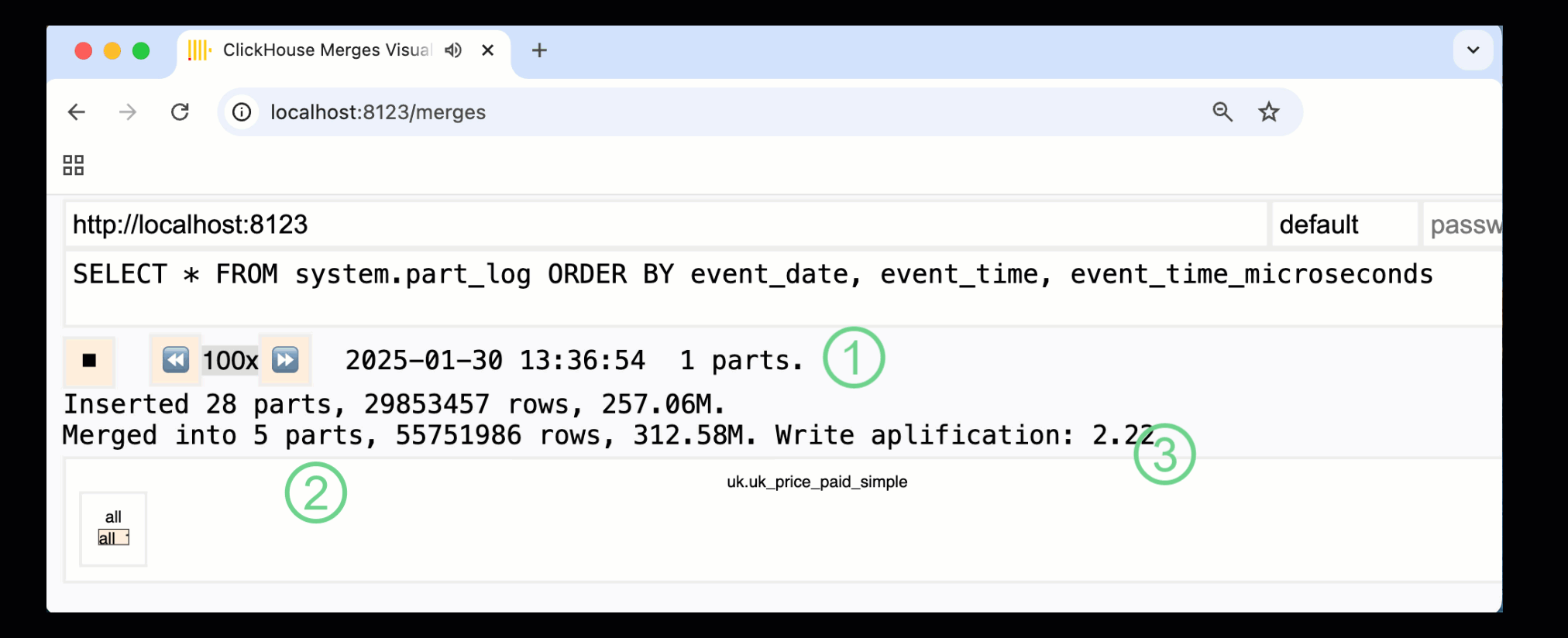
Записанная выше панель мониторинга захватывает весь процесс, начиная с начальных вставок данных и заканчивая финальным слиянием в одну часть:
① Количество активных ^^частей^^.
② Слияния частей, визуально представленные с помощью прямоугольников (размер отражает размер части).
Параллельные слияния
Один сервер ClickHouse использует несколько фоновых потоков слияния для выполнения параллельных слияний частей:
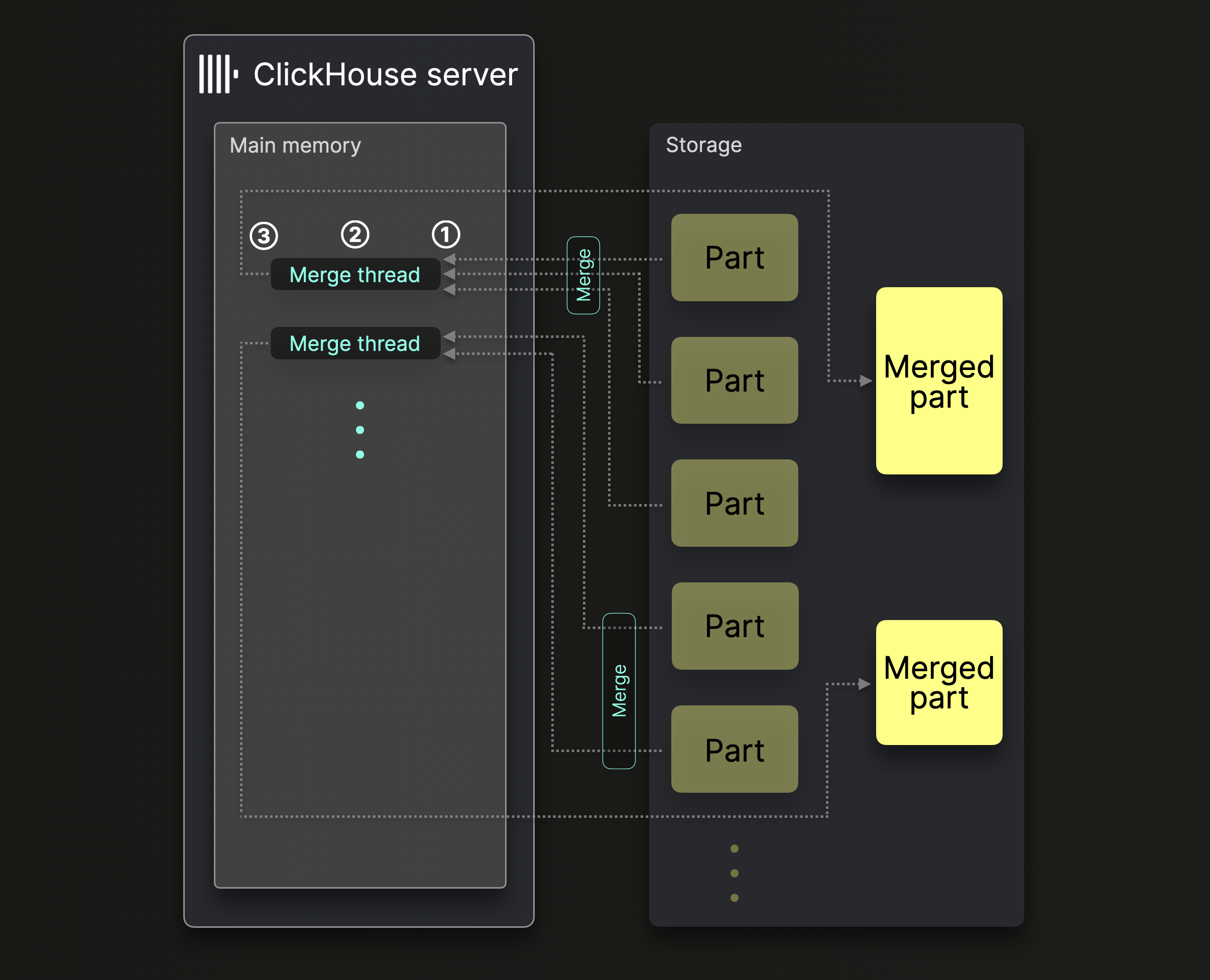
Каждый поток слияния выполняет цикл:
① Решает, какие ^^части^^ слить следующими, и загружает эти ^^части^^ в память.
② Сливает ^^части^^ в памяти в большую часть.
③ Записывает слитую часть на диск.
Вернуться к ①
Обратите внимание, что увеличение количества ядер CPU и объема ОЗУ позволяет увеличить пропускную способность фонового слияния.
Оптимизированные по памяти слияния
ClickHouse не обязательно загружает все ^^части^^, которые подлежат слиянию, в память одновременно, как это показано в предыдущем примере. На основе нескольких факторов, и для сокращения потребления памяти (пожертвовав скоростью слияния), так называемое вертикальное слияние загружает и сливает ^^части^^ по частям блоков, а не за один раз.
Механика слияния
Диаграмма ниже иллюстрирует, как один фоновый поток слияния в ClickHouse сливает ^^части^^ (по умолчанию, без вертикального слияния):
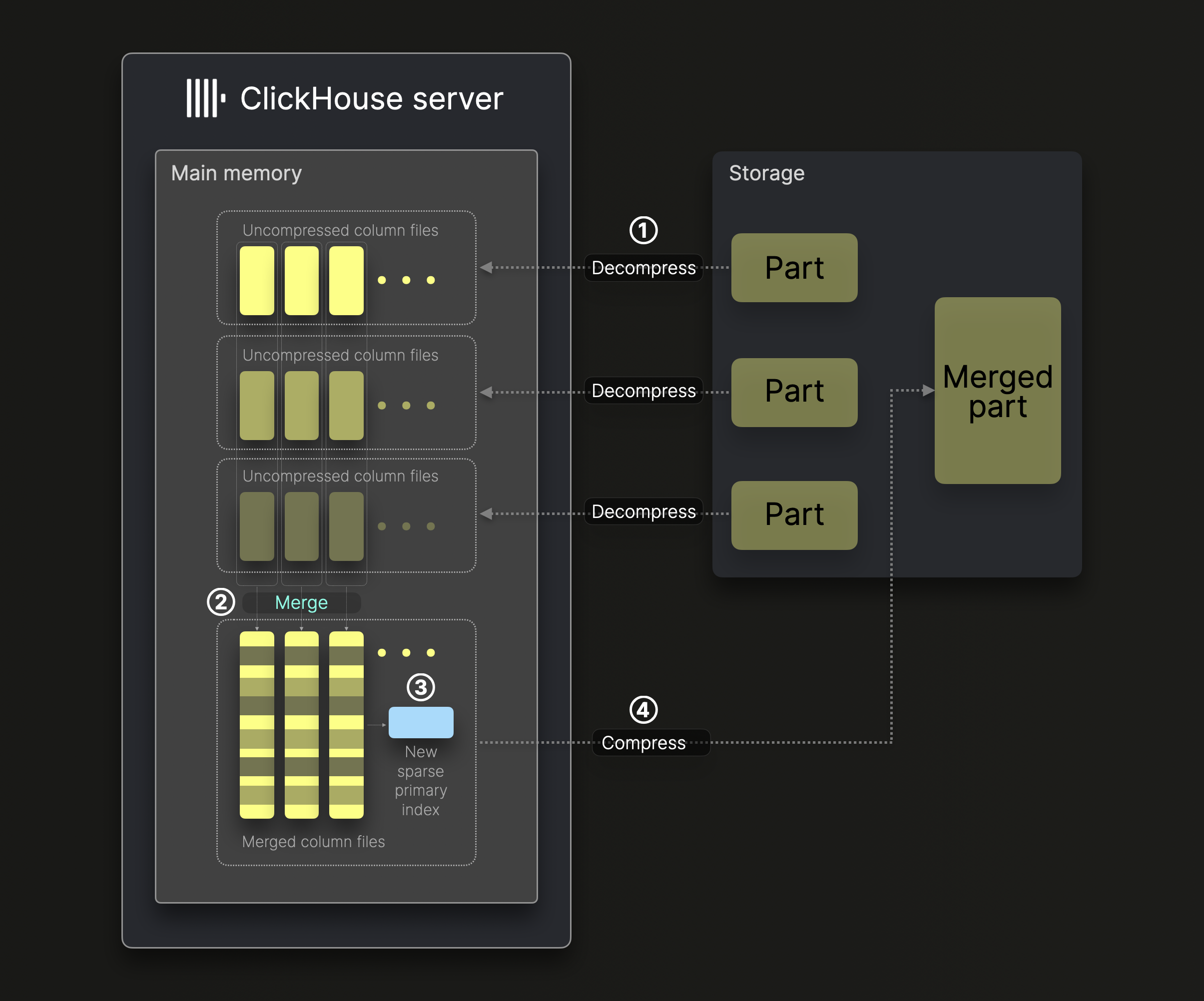
Слияние частей выполняется в несколько этапов:
① Декодирование и загрузка: Сжатые бинарные файлы колонок из ^^частей^^, подлежащих слиянию, декодируются и загружаются в память.
② Слияние: Данные сливаются в более крупные файлы колонок.
③ Индексирование: Создается новый разреженный первичный индекс для слитых файлов колонок.
④ Сжатие и хранение: Новые файлы колонок и индекс сжимаются и сохраняются в новой директории, представляющей слитую часть данных.
Дополнительные метаданные в частях данных, такие как вторичные индексы пропуска данных, статистика по колонкам, контрольные суммы и мин-макс индексы, также восстанавливаются на основе слитых файлов колонок. Мы пропустили эти детали для простоты.
Механика этапа ② зависит от конкретного движка MergeTree, так как разные движки обрабатывают слияние по-разному. Например, строки могут быть агрегированы или заменены, если устарели. Как упоминалось ранее, этот подход перегружает всю обработку данных на фоновые слияния, позволяя супербыстрые вставки, поддерживая операции записи легковесными и эффективными.
В следующем разделе мы кратко опишем механику слияния конкретных движков в ^^MergeTree^^ семейства.
Стандартные слияния
Диаграмма ниже иллюстрирует, как ^^части^^ в стандартной MergeTree таблице сливаются:
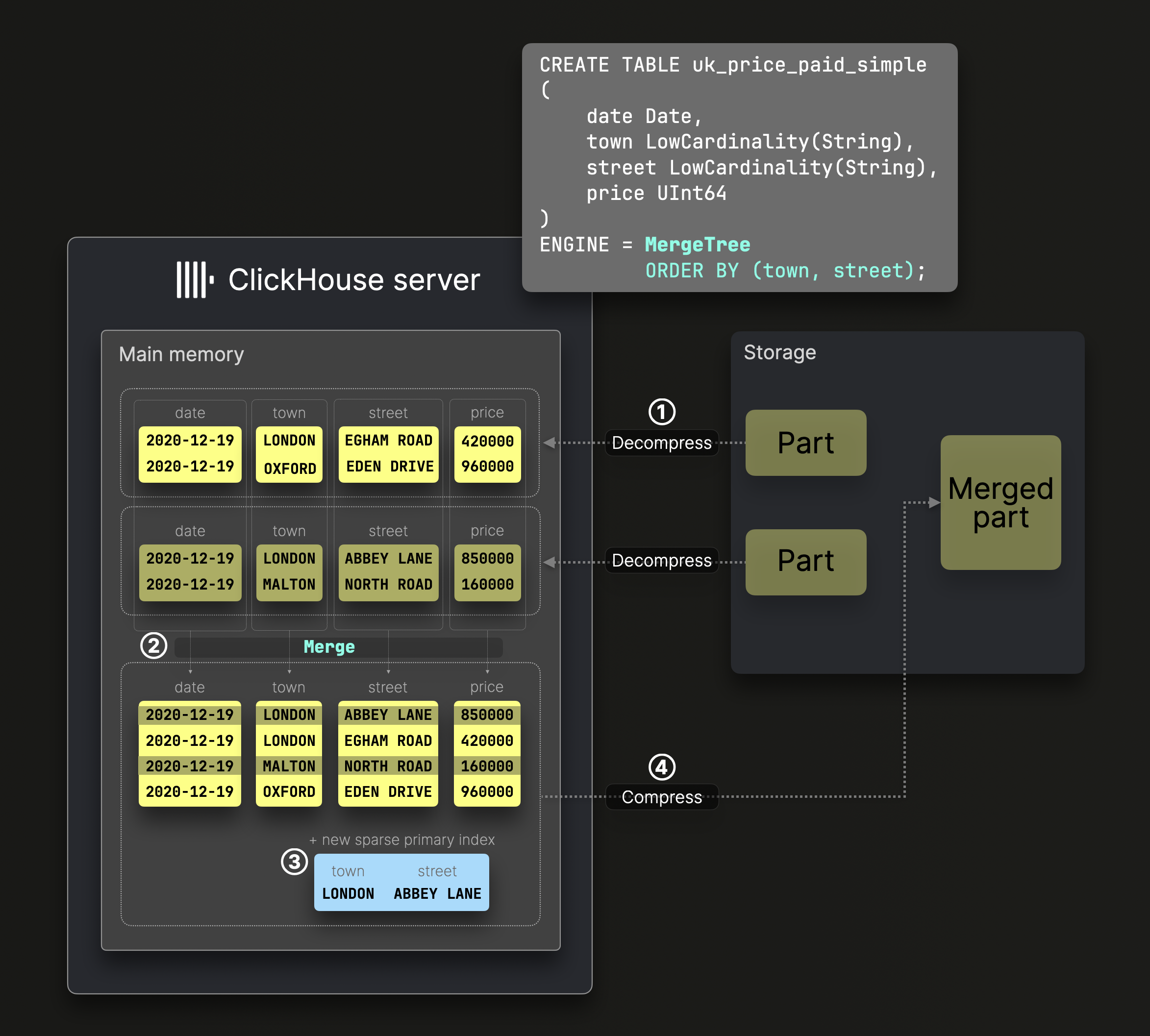
DDL-оператор на диаграмме выше создает таблицу MergeTree с ^^ключом сортировки^^ (town, street), что означает, что данные на диске отсортированы по этим колонкам, и создается соответствующий разреженный первичный индекс.
Сначала ① декомпрессированные, предварительно отсортированные колонки таблицы ② сливаются, сохраняя глобальный порядок сортировки таблицы, определяемый ^^ключом сортировки^^ таблицы, ③ создается новый разреженный первичный индекс, и ④ слитые файлы колонок и индекс сжимаются и сохраняются как новая часть данных на диске.
Заменяющие слияния
Слияния частей в таблице ReplacingMergeTree работают аналогично стандартным слияниям, но только самая последняя версия каждой строки сохраняется, а более старые версии отбрасываются:
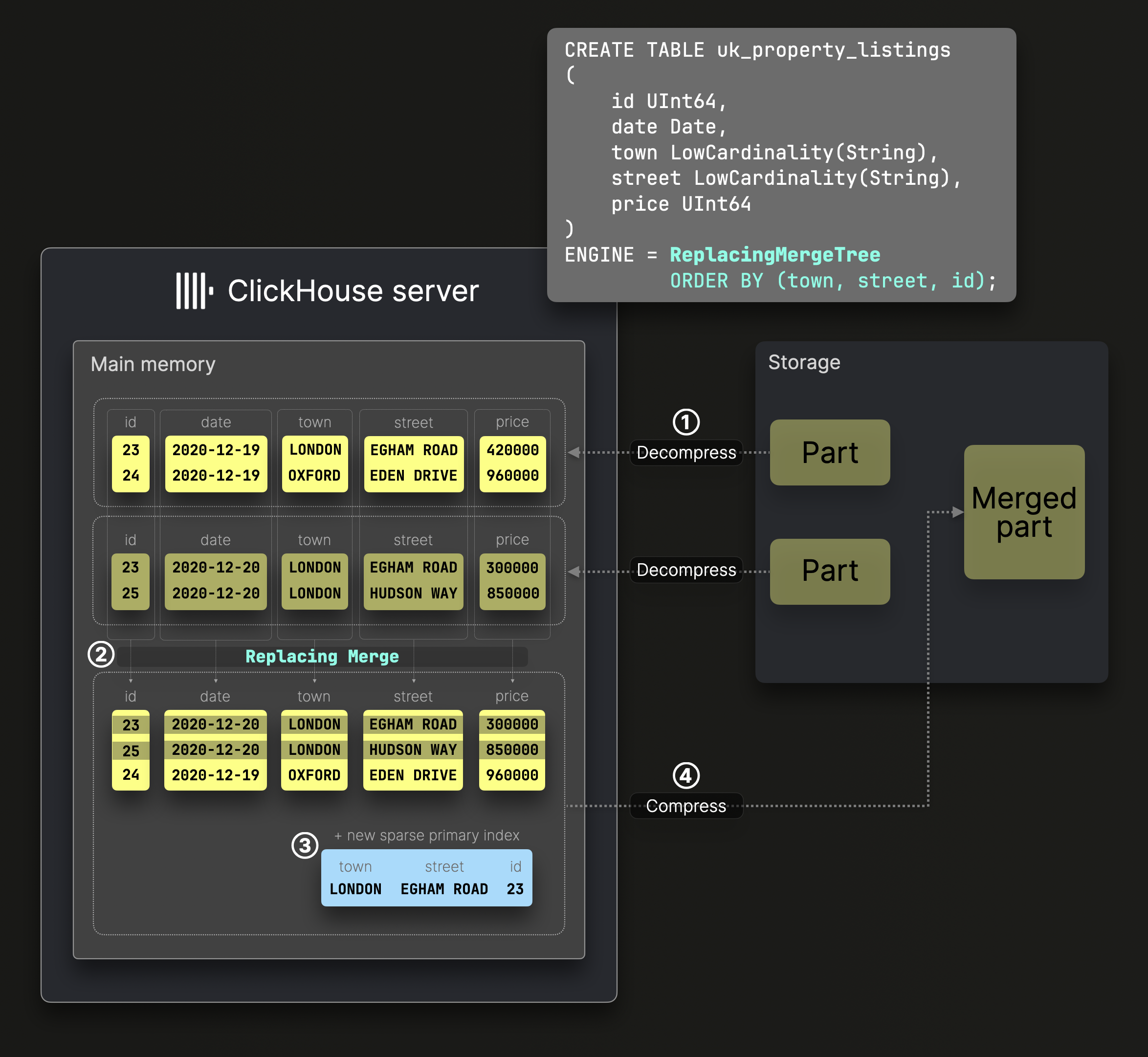
DDL-оператор на диаграмме выше создает таблицу ReplacingMergeTree с ^^ключом сортировки^^ (town, street, id), что означает, что данные на диске отсортированы по этим колонкам, с соответствующим разреженным первичным индексом.
Процесс ② слияния аналогичен слиянию в стандартной таблице MergeTree, объединяя декомпрессированные, предварительно отсортированные колонки при сохранении глобального порядка сортировки.
Тем не менее, ReplacingMergeTree удаляет дубликаты строк с одинаковым ^^ключом сортировки^^, сохраняя только самую последнюю строку на основе временной метки создания ее содержащей части.
Суммирующие слияния
Числовые данные автоматически суммируются во время слияний ^^частей^^ из таблицы SummingMergeTree:
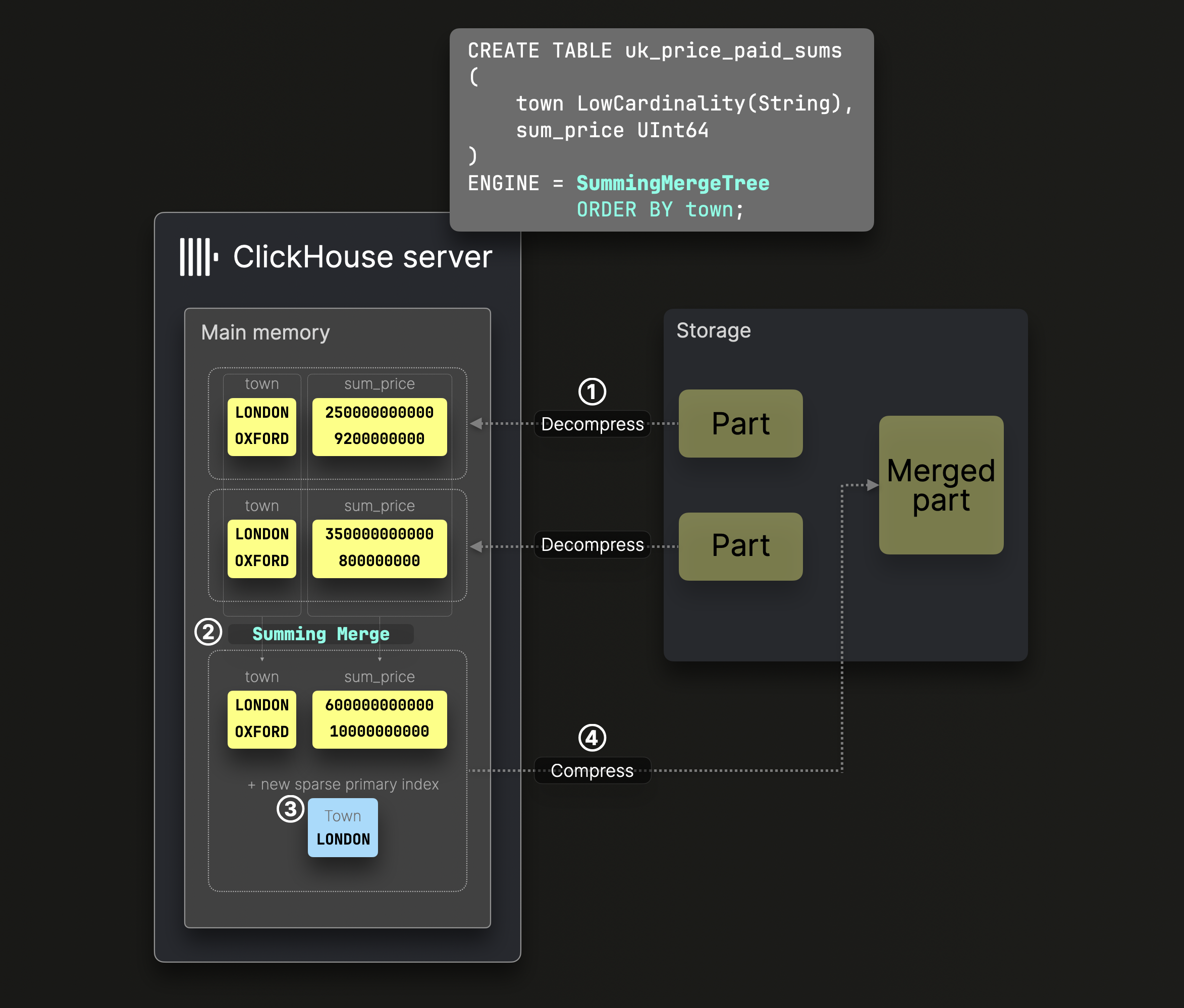
DDL-оператор на диаграмме выше определяет таблицу SummingMergeTree с town в качестве ^^ключа сортировки^^, что означает, что данные на диске отсортированы по этому столбцу, и создается соответствующий разреженный первичный индекс.
На этапе ② слияния ClickHouse заменяет все строки с одинаковым ^^ключом сортировки^^ на одну строку, суммируя значения числовых колонок.
Агрегационные слияния
Пример таблицы SummingMergeTree, упомянутый выше, является специализированным вариантом таблицы AggregatingMergeTree, позволяющим автоматическую инкрементальную трансформацию данных путем применения любой из 90+ агрегатных функций во время слияний частей:
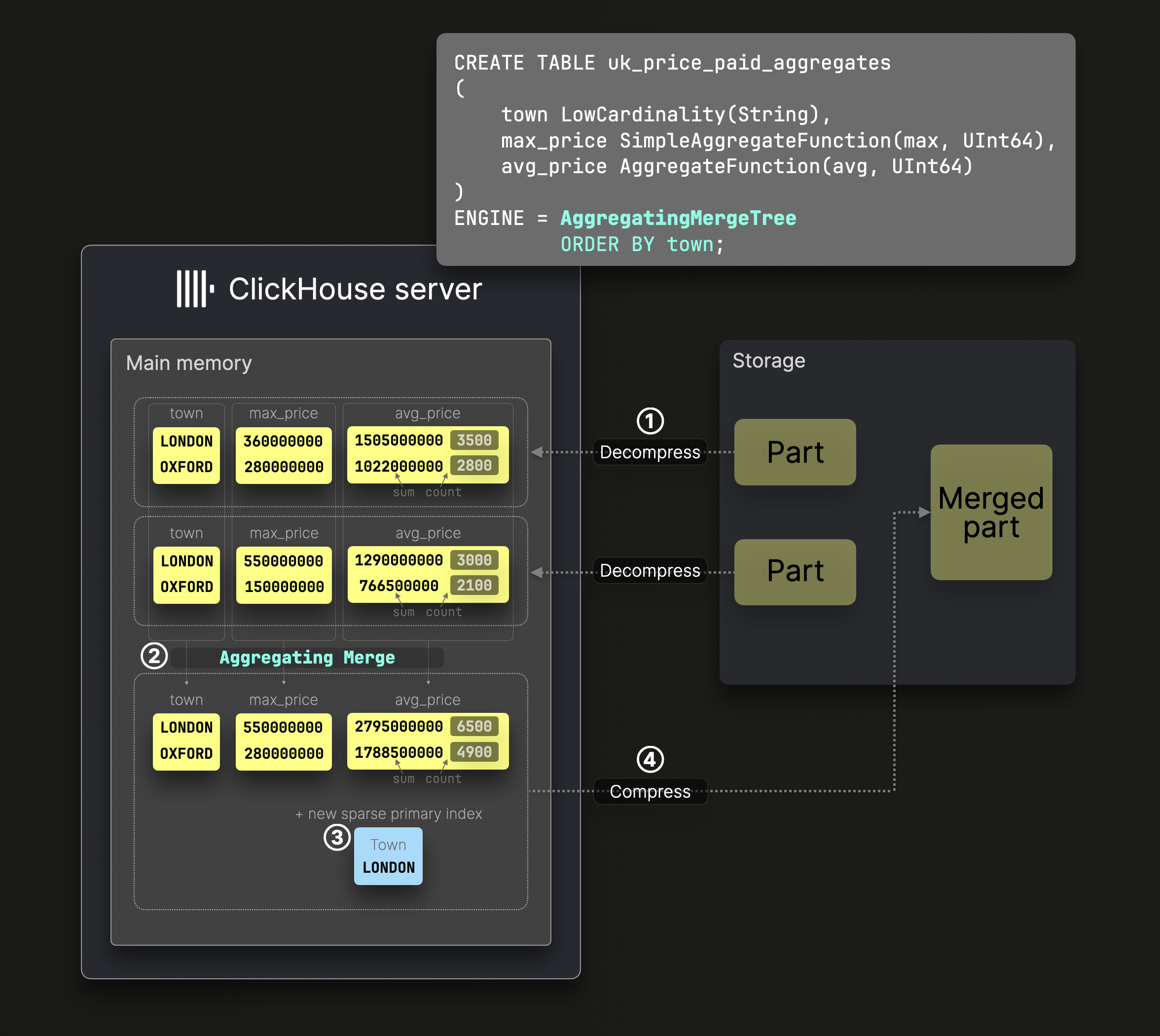
DDL-оператор на диаграмме выше создает таблицу AggregatingMergeTree с town в качестве ^^ключа сортировки^^, что гарантирует, что данные упорядочены по этому столбцу на диске, и создается соответствующий разреженный первичный индекс.
Во время ② слияния ClickHouse заменяет все строки с одинаковым ^^ключом сортировки^^ на одну строку, хранящую частичные состояния агрегации (например, sum и count для avg()). Эти состояния обеспечивают точные результаты через инкрементальные фоновые слияния.
