Как работает оптимизация PREWHERE?
Оператор PREWHERE — это оптимизация выполнения запросов в ClickHouse. Он снижает ввод-вывод и улучшает скорость выполнения запросов, избегая ненужных чтений данных и фильтруя нерелевантные данные до чтения столбцов без фильтров с диска.
Этот руководств объясняет, как работает PREWHERE, как измерить его влияние и как настроить его для достижения наилучшей производительности.
Обработка запросов без оптимизации PREWHERE
Начнем с иллюстрации обработки запроса к таблице uk_price_paid_simple без использования PREWHERE:

① Запрос включает фильтр по столбцу town, который является частью первичного ключа таблицы и, следовательно, также частью первичного индекса.
② Для ускорения запроса ClickHouse загружает первичный индекс таблицы в память.
③ Он сканирует записи индекса, чтобы определить, какие гранулы из столбца town могут содержать строки, соответствующие предикату.
④ Эти потенциально релевантные гранулы загружаются в память вместе с позиционно согласованными гранулами из любых других столбцов, необходимых для запроса.
⑤ Оставшиеся фильтры затем применяются во время выполнения запроса.
Как видно, без PREWHERE все потенциально релевантные столбцы загружаются перед фильтрацией, даже если только несколько строк фактически соответствуют.
Как PREWHERE улучшает эффективность запроса
Следующие анимации показывают, как обработка запроса выше происходит с применением оператора PREWHERE ко всем предикатам запроса.
Первые три шага обработки такие же, как и прежде:

① Запрос включает фильтр по столбцу town, который является частью первичного ключа таблицы и, следовательно, также частью первичного индекса.
② Аналогично выполнению без оператора PREWHERE, для ускорения запроса ClickHouse загружает первичный индекс в память,
③ затем сканирует записи индекса, чтобы определить, какие гранулы из столбца town могут содержать строки, соответствующие предикату.
Теперь, благодаря оператору PREWHERE, следующий шаг отличается: вместо того, чтобы считывать все релевантные столбцы сразу, ClickHouse фильтрует данные по каждому столбцу, загружая только то, что действительно необходимо. Это значительно снижает ввод-вывод, особенно для широких таблиц.
На каждом шаге загружаются только гранулы, содержащие хотя бы одну строку, которая прошла — т.е. соответствовала — предыдущему фильтру. В результате количество гранул, которые нужно загрузить и оценить для каждого фильтра, уменьшается монотонно:
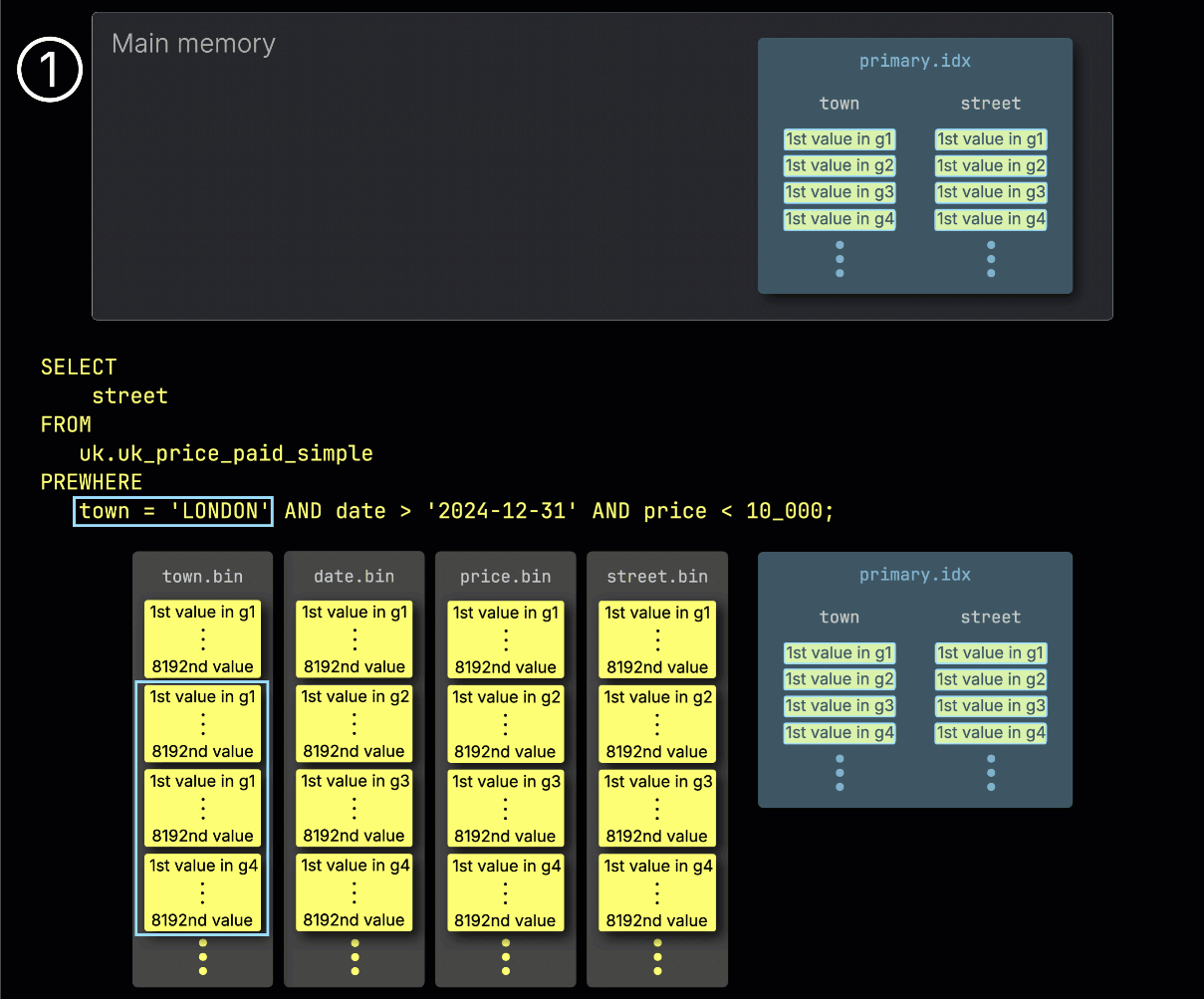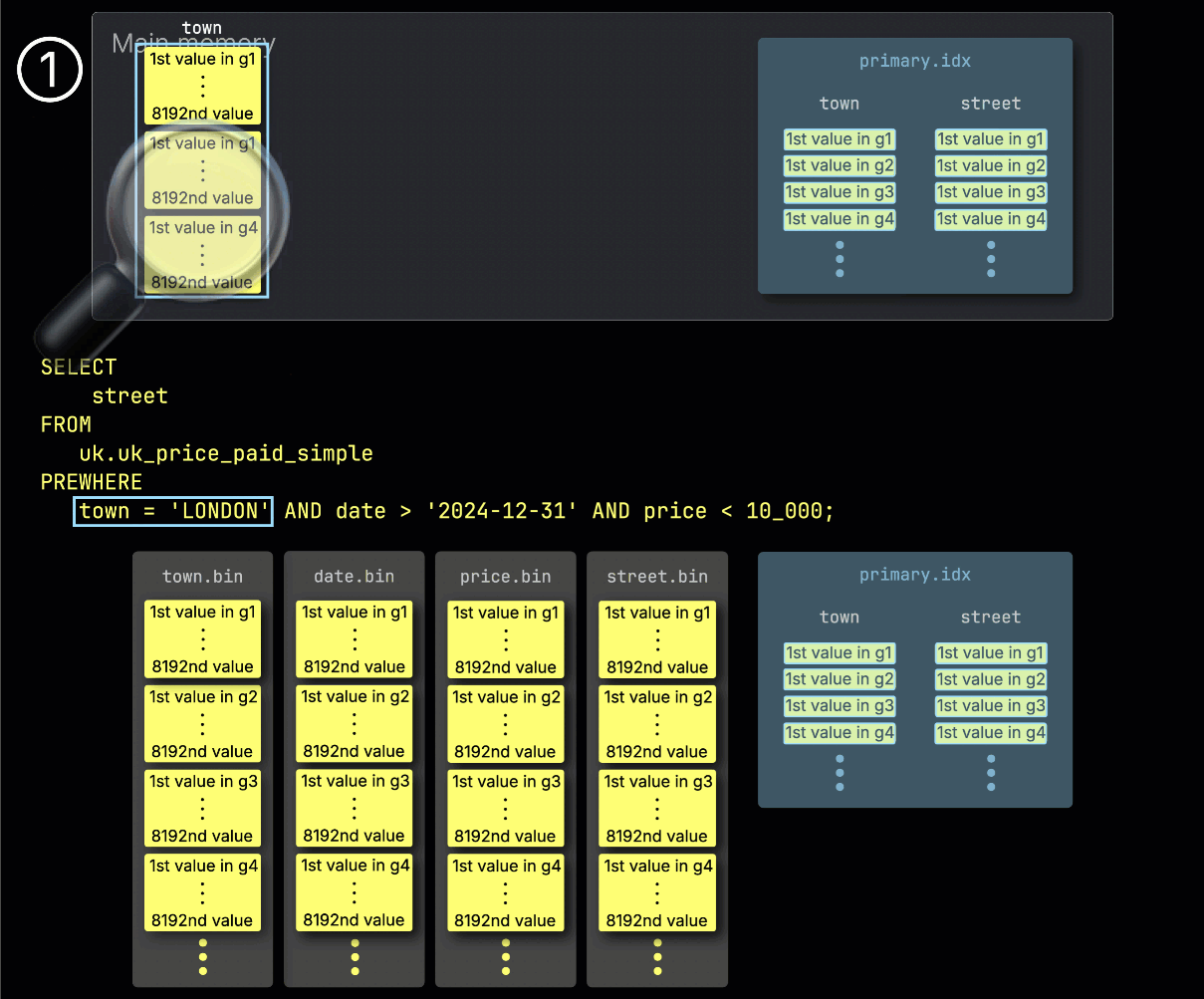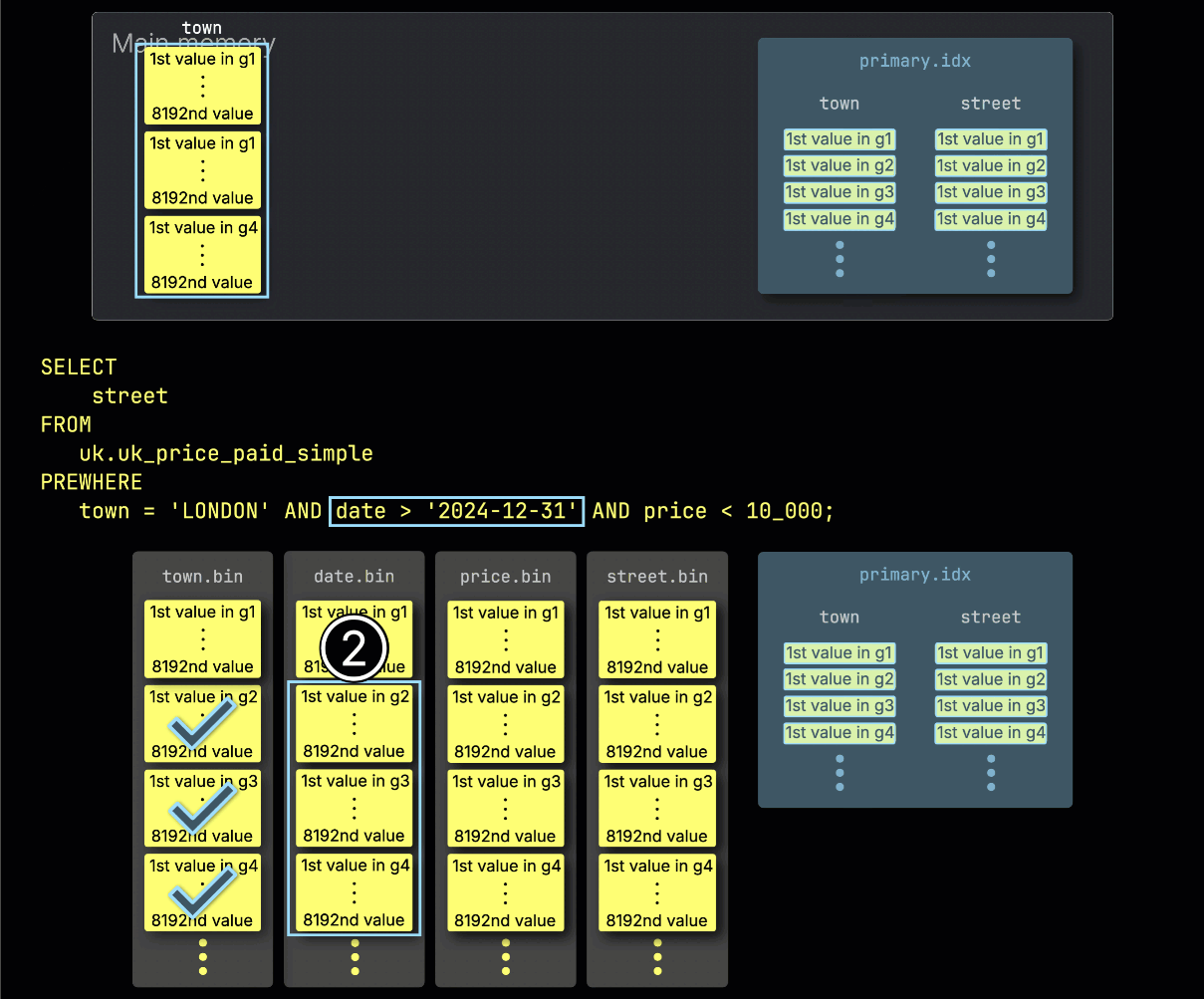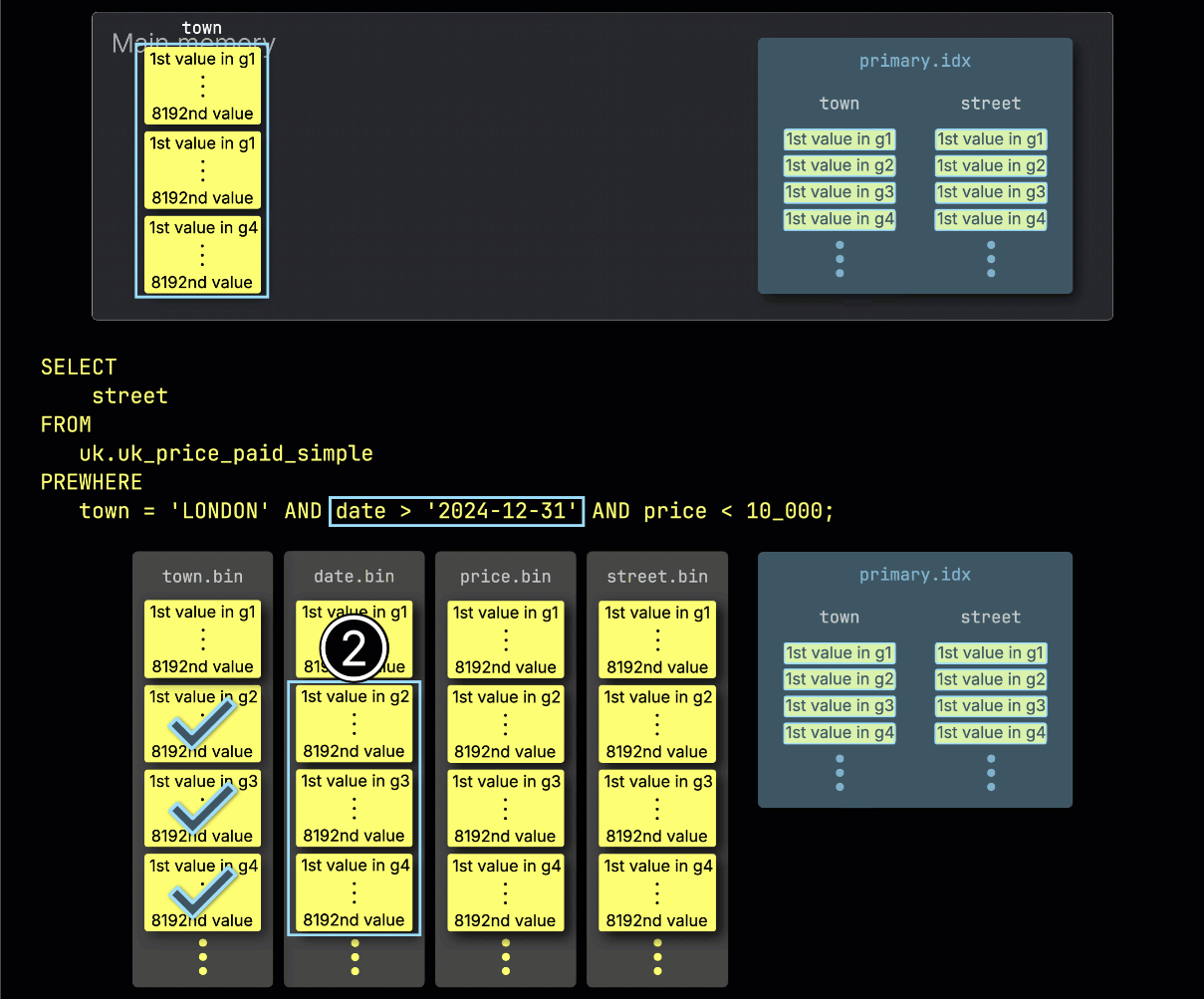
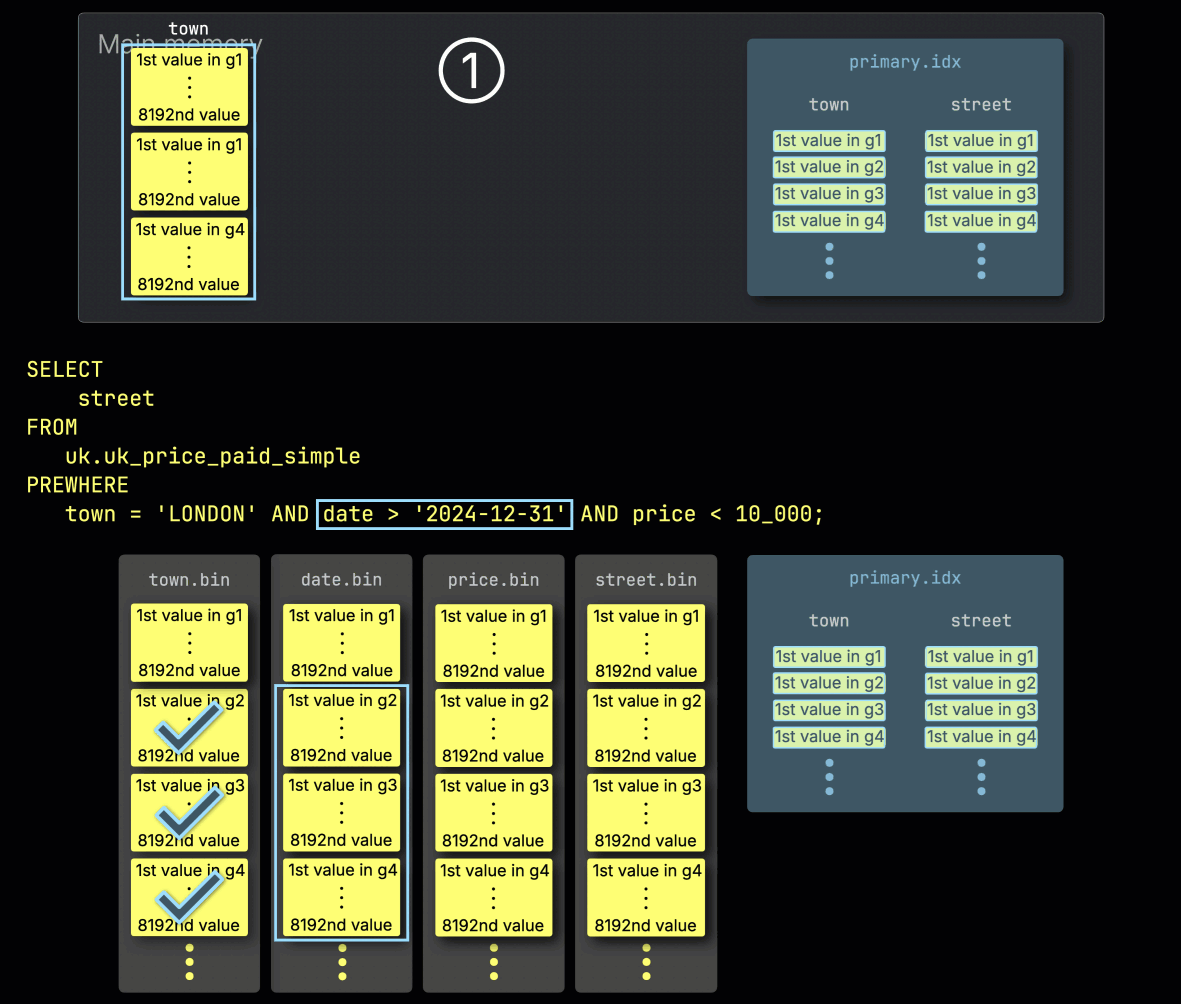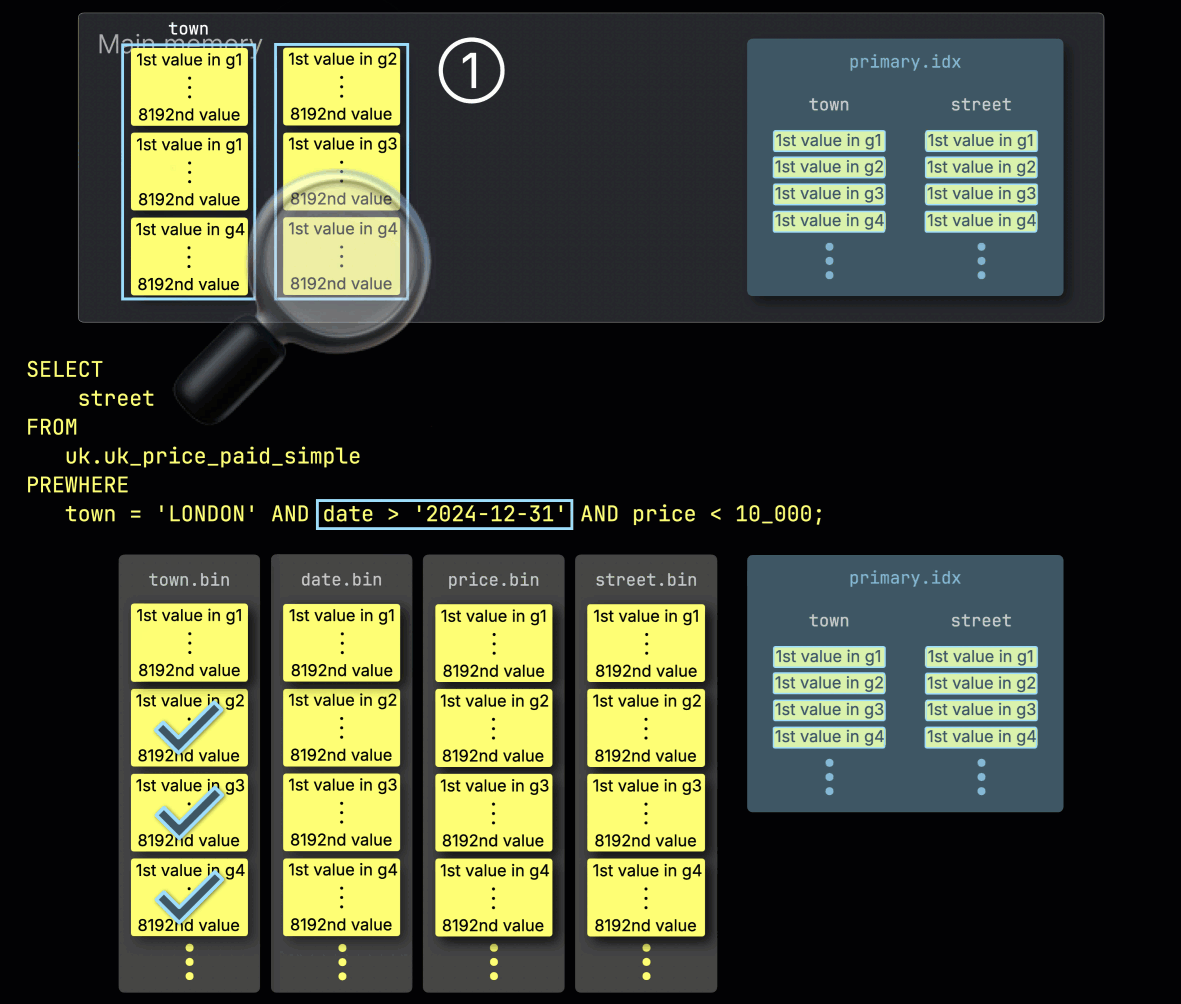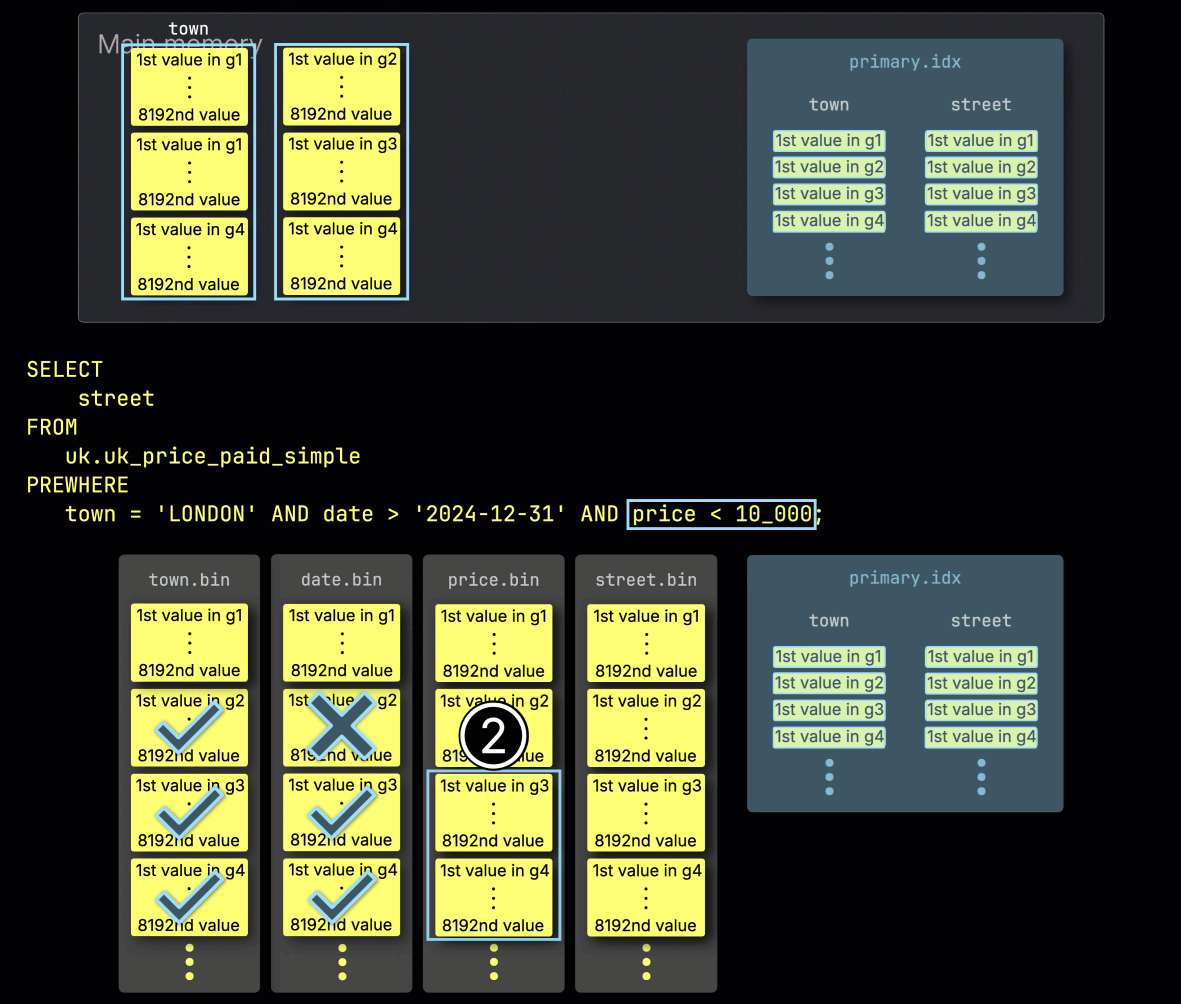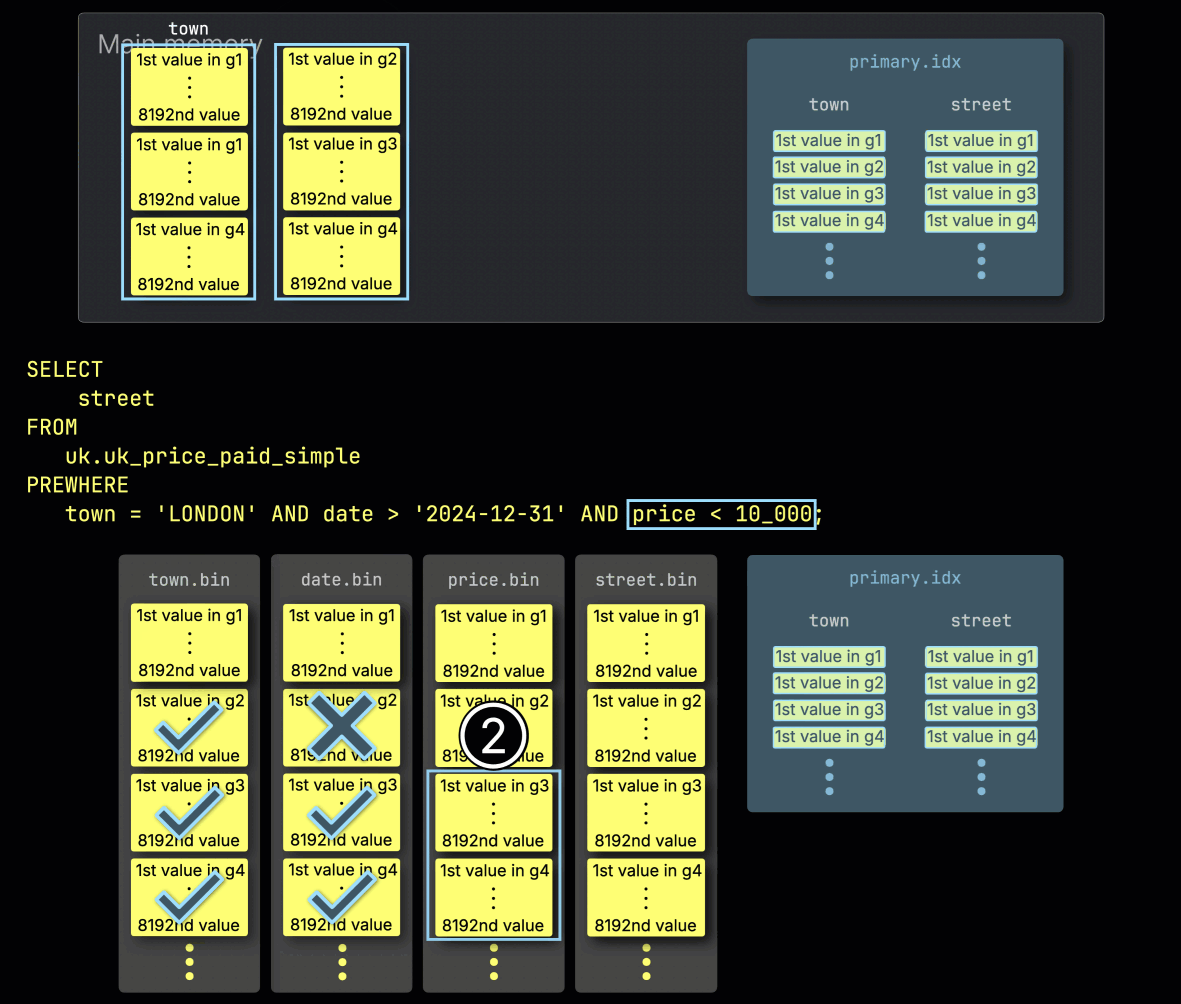
Шаг 1: Фильтрация по городу
ClickHouse начинает обработку PREWHERE, ① считывая выбранные гранулы из столбца town и проверяя, какие из них действительно содержат строки, соответствующие London.
В нашем примере все выбранные гранулы соответствуют, поэтому ② выбираются соответствующие позиционно согласованные гранулы для следующего столбца фильтра — date — для обработки:
Шаг 2: Фильтрация по дате
Далее ClickHouse ① считывает выбранные гранулы из столбца date, чтобы оценить фильтр date > '2024-12-31'.
В этом случае два из трех гранул содержат соответствующие строки, поэтому ② только их позиционно согласованные гранулы из следующего столбца фильтра — price — выбираются для дальнейшей обработки:
Шаг 3: Фильтрация по цене
Наконец, ClickHouse ① считывает два выбранных гранула из столбца price, чтобы оценить последний фильтр price > 10_000.
Только один из двух гранул содержит соответствующие строки, поэтому ② требуется загрузить только его позиционно согласованный гранул из столбца SELECT — street — для дальнейшей обработки:

На финальном шаге загружается только минимальный набор гранул столбцов, содержащих соответствующие строки. Это приводит к более низкому использованию памяти, меньшему вводу-выводу с диска и более быстрому выполнению запроса.
Обратите внимание, что ClickHouse обрабатывает одно и то же количество строк как в версиях запроса с PREWHERE, так и без него. Однако с применением оптимизации PREWHERE не все значения столбцов необходимо загружать для каждой обрабатываемой строки.
Оптимизация PREWHERE применяется автоматически
Оператор PREWHERE можно добавить вручную, как показано в примере выше. Однако нет необходимости писать PREWHERE вручную. Когда настройка optimize_move_to_prewhere включена (по умолчанию true), ClickHouse автоматически перемещает условия фильтрации из WHERE в PREWHERE, приоритизируя те, которые максимизируют снижение объема чтения.
Идея заключается в том, что меньшие столбцы быстрее сканируются, и к моменту обработки больших столбцов большинство гранул уже отфильтровано. Поскольку все столбцы имеют одинаковое количество строк, размер столбца в основном определяется его типом данных, например, столбец UInt8 обычно значительно меньше, чем столбец String.
ClickHouse по умолчанию следует этой стратегии с версии 23.2, сортируя столбцы фильтра PREWHERE для многоэтапной обработки в порядке возрастания не сжатого размера.
Начиная с версии 23.11, необязательные статистики столбцов могут дополнительно улучшить это, выбирая порядок обработки фильтров на основе фактической избирательности данных, а не только размера столбца.
Как измерить влияние PREWHERE
Чтобы подтвердить, что PREWHERE помогает вашим запросам, вы можете сравнить производительность запроса с включенной и отключенной настройкой optimize_move_to_prewhere.
Начнем с выполнения запроса с отключенной настройкой optimize_move_to_prewhere:
ClickHouse прочитал 23.36 МБ данных столбца, обрабатывая 2.31 миллиона строк для запроса.
Затем мы запускаем запрос с включенной настройкой optimize_move_to_prewhere. (Обратите внимание, что эта настройка является необязательной, так как она включена по умолчанию):
То же количество строк было обработано (2.31 миллиона), но благодаря PREWHERE ClickHouse прочитал более чем в три раза меньше данных столбца — всего 6.74 МБ вместо 23.36 МБ — что сократило общее время выполнения в 3 раза.
Для более глубокого понимания того, как ClickHouse применяет PREWHERE за кулисами, используйте EXPLAIN и журналы трассировки.
Мы проверяем логический план запроса, используя оператор EXPLAIN:
Мы опускаем большую часть вывода плана здесь, так как он довольно объемный. По сути, он показывает, что все три предиката столбца были автоматически перемещены в PREWHERE.
При воспроизведении этого самостоятельно вы также увидите в плане запроса, что порядок этих предикатов основан на размерах типов данных столбцов. Поскольку мы не включили статистику столбцов, ClickHouse использует размер в качестве аварийного варианта для определения порядка обработки PREWHERE.
Если вы хотите заглянуть еще глубже, вы можете наблюдать каждый отдельный шаг обработки PREWHERE, указав ClickHouse вернуть все записи журнала на уровне тестирования во время выполнения запроса:
Основные выводы
- PREWHERE избегает чтения данных столбца, которые затем будут отфильтрованы, экономя ввод-вывод и память.
- Он работает автоматически, когда включена настройка
optimize_move_to_prewhere(по умолчанию). - Порядок фильтрации имеет значение: маленькие и избирательные столбцы должны быть первыми.
- Используйте
EXPLAINи журналы, чтобы проверить, что PREWHERE применен, и понять его эффект. - PREWHERE наиболее эффективно работает на широких таблицах и при больших сканированиях с избирательными фильтрами.
