Как ClickHouse выполняет запрос параллельно
ClickHouse создан для скорости. Он выполняет запросы в высокопараллельном режиме, используя все доступные ядра CPU, распределяя данные по обработчикам и зачастую приближая оборудование к его пределам.
Этот гид объясняет, как работает параллелизм запросов в ClickHouse и как вы можете настроить или контролировать его для улучшения производительности на больших нагрузках.
Мы используем запрос агрегации на наборе данных uk_price_paid_simple, чтобы проиллюстрировать ключевые концепции.
Пошагово: Как ClickHouse параллелизует запрос агрегации
Когда ClickHouse ① выполняет запрос агрегации с фильтром по первичному ключу таблицы, он ② загружает первичный индекс в память, чтобы ③ определить, какие гранулы нужно обработать, а какие можно безопасно пропустить:
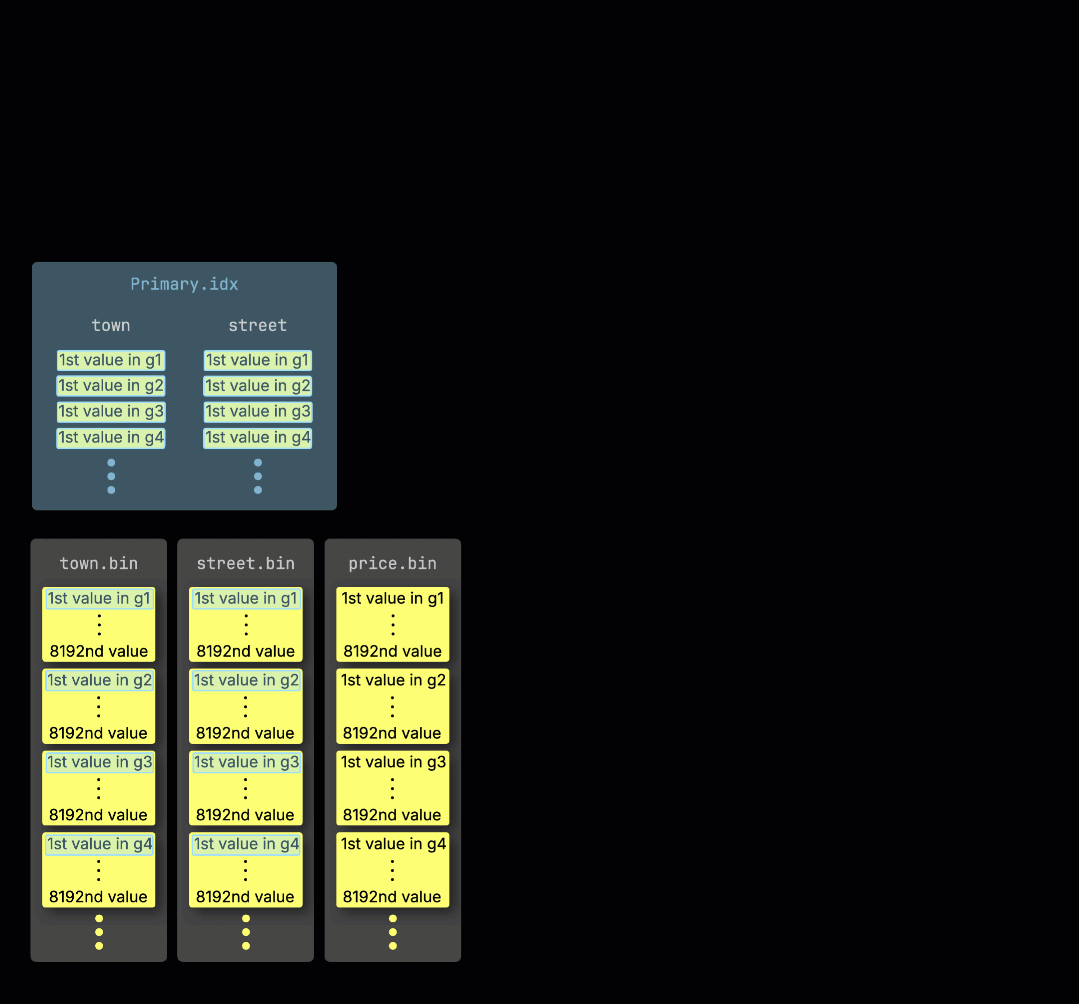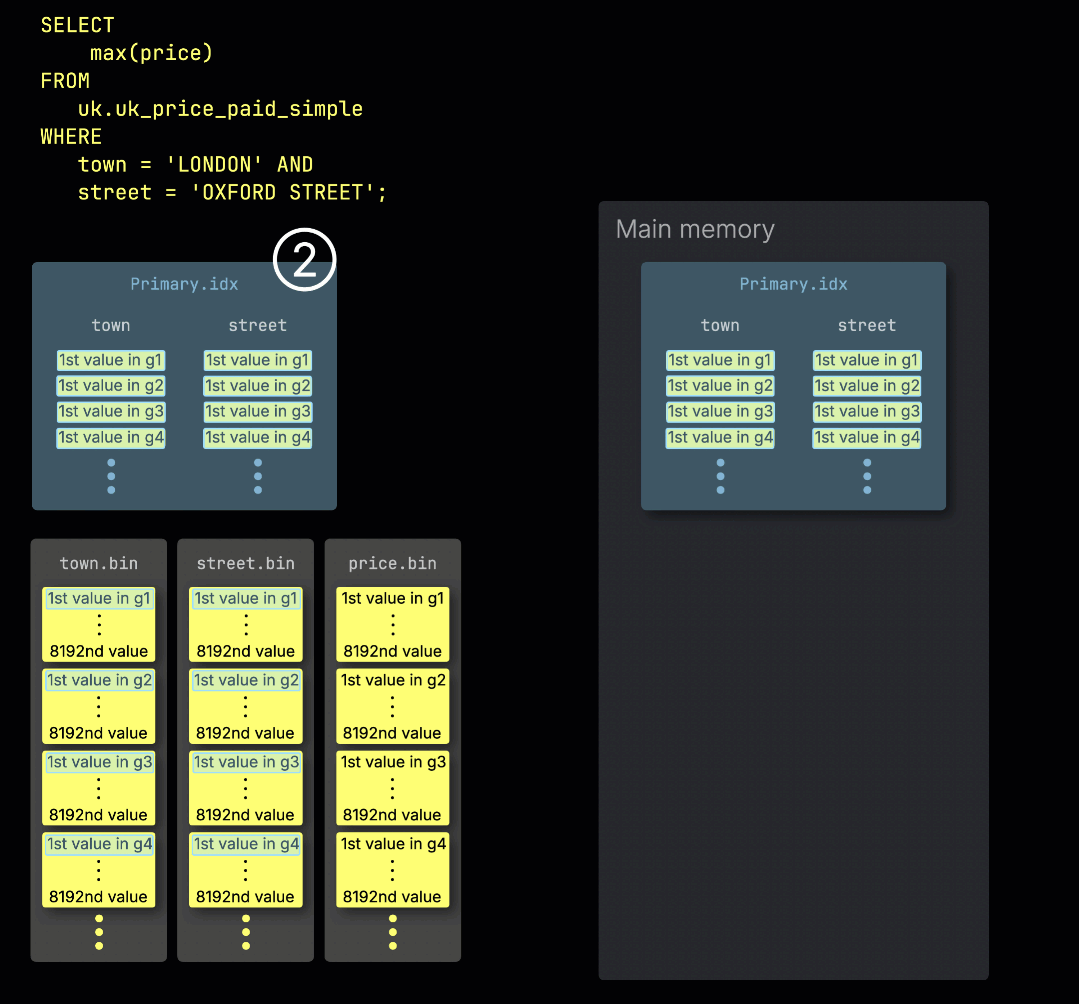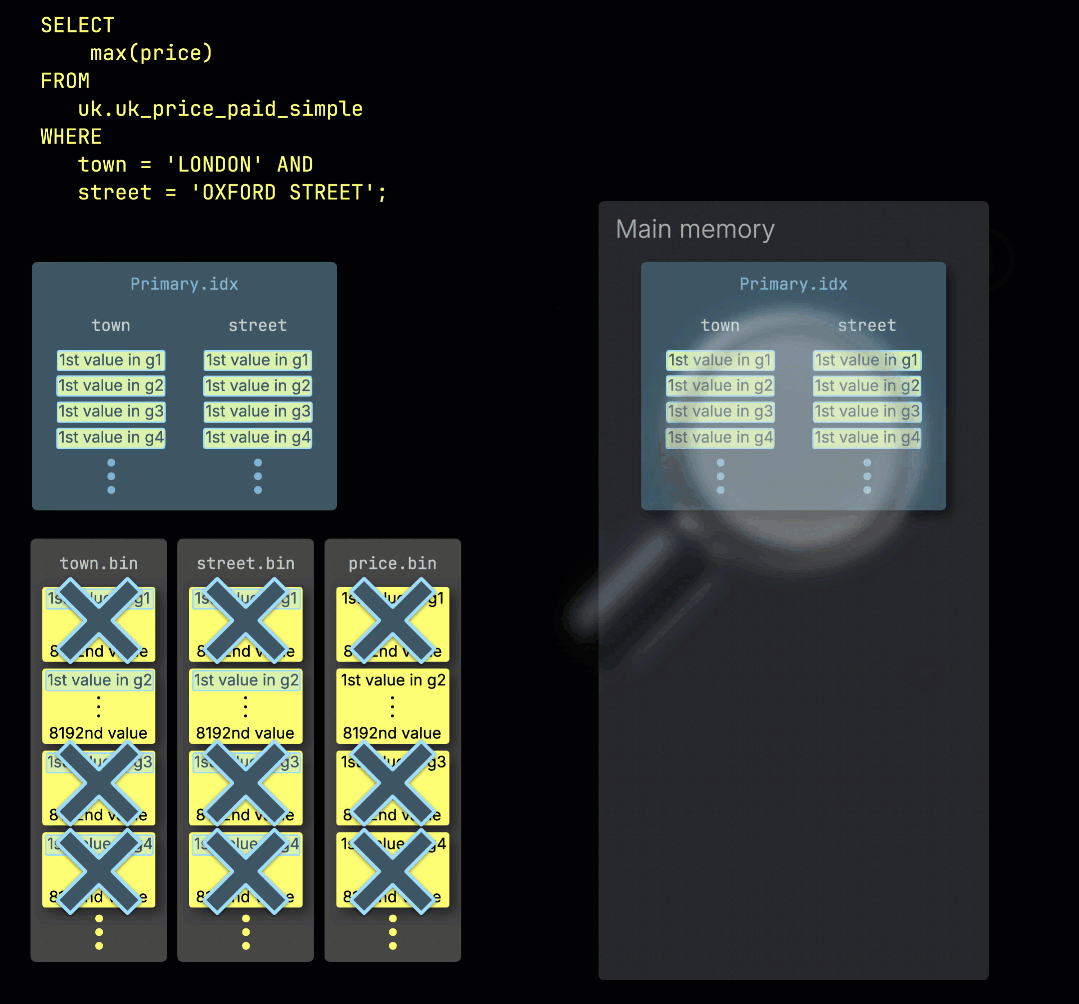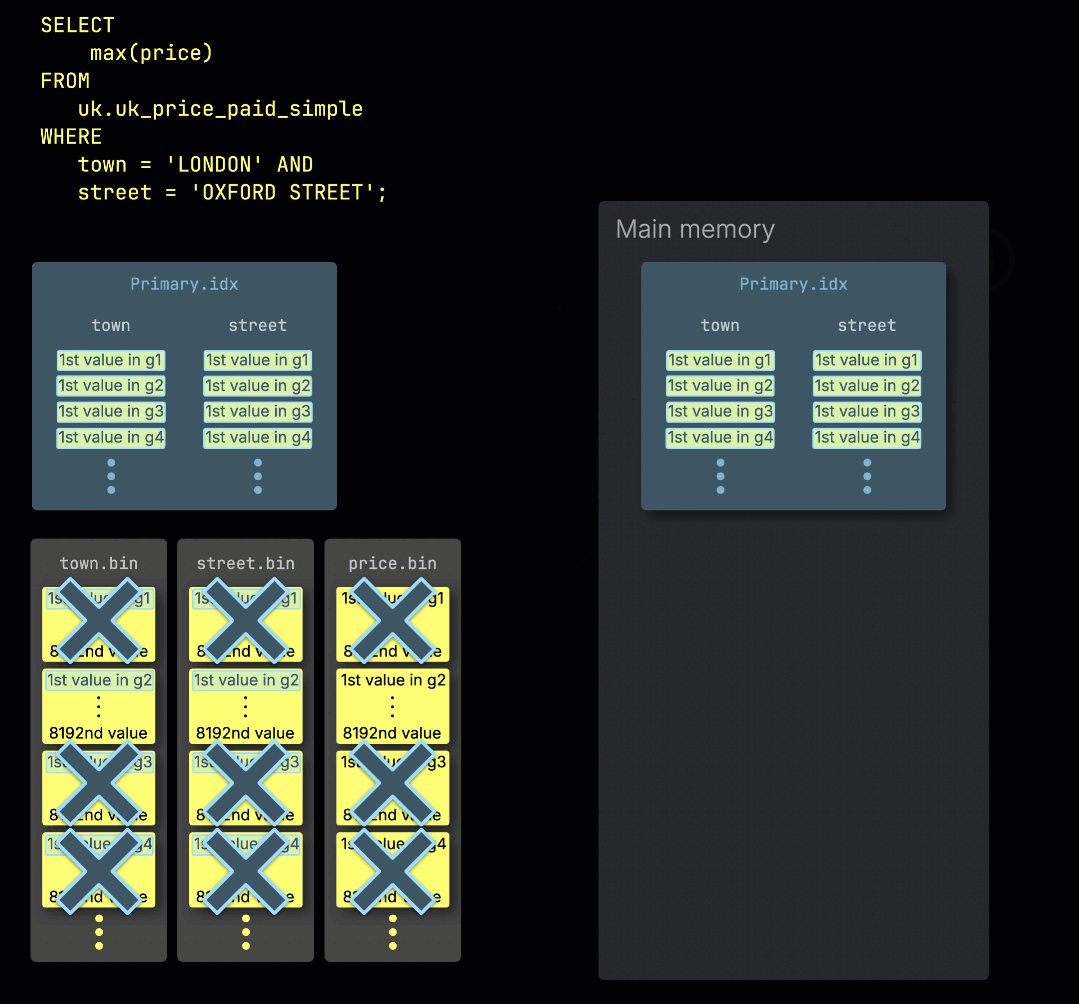
Распределение работы по обработчикам
Выбранные данные затем динамически распределяются по n параллельным обработчикам, которые поточно обрабатывают данные блок за блоком и формируют итоговый результат:
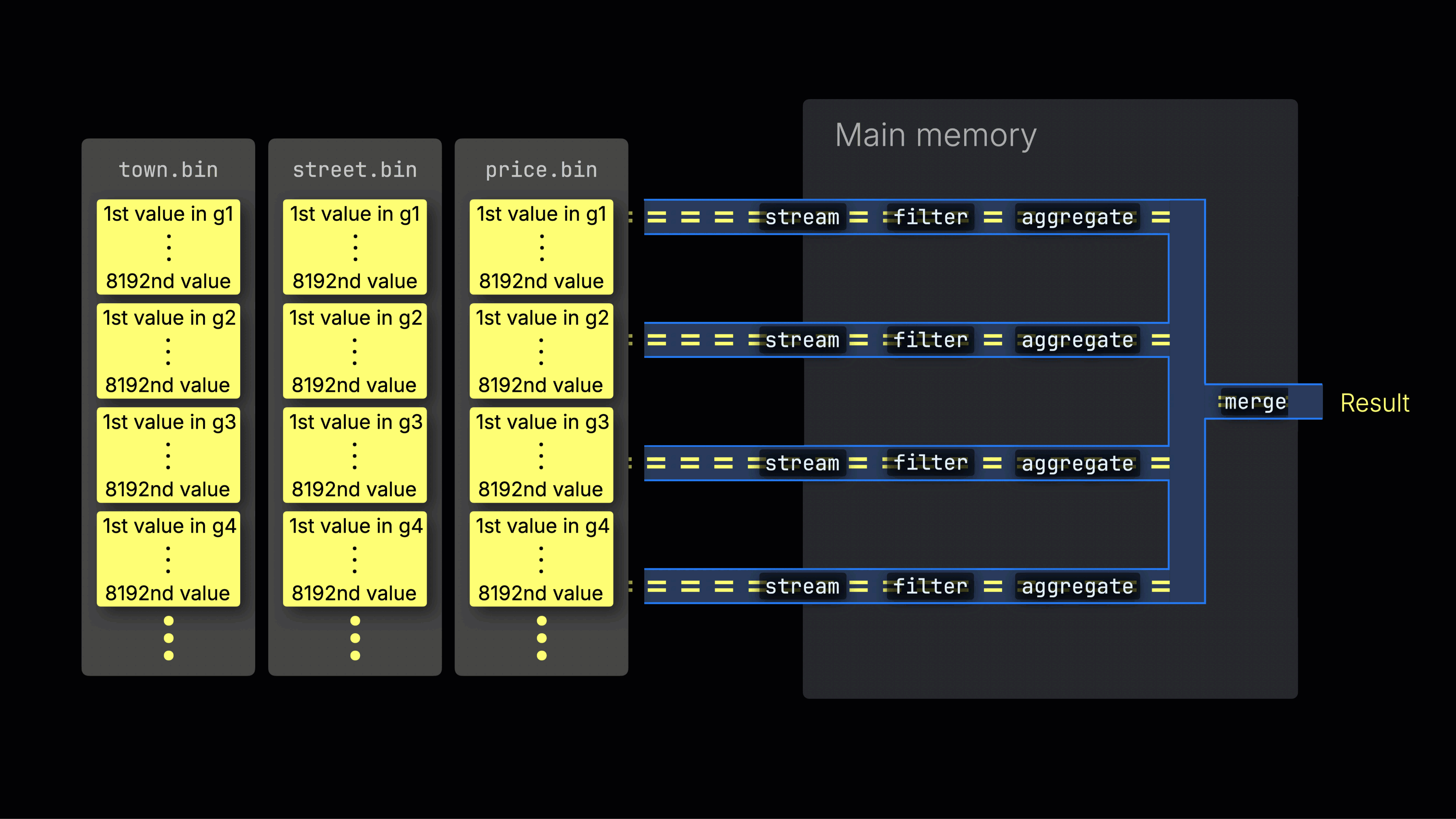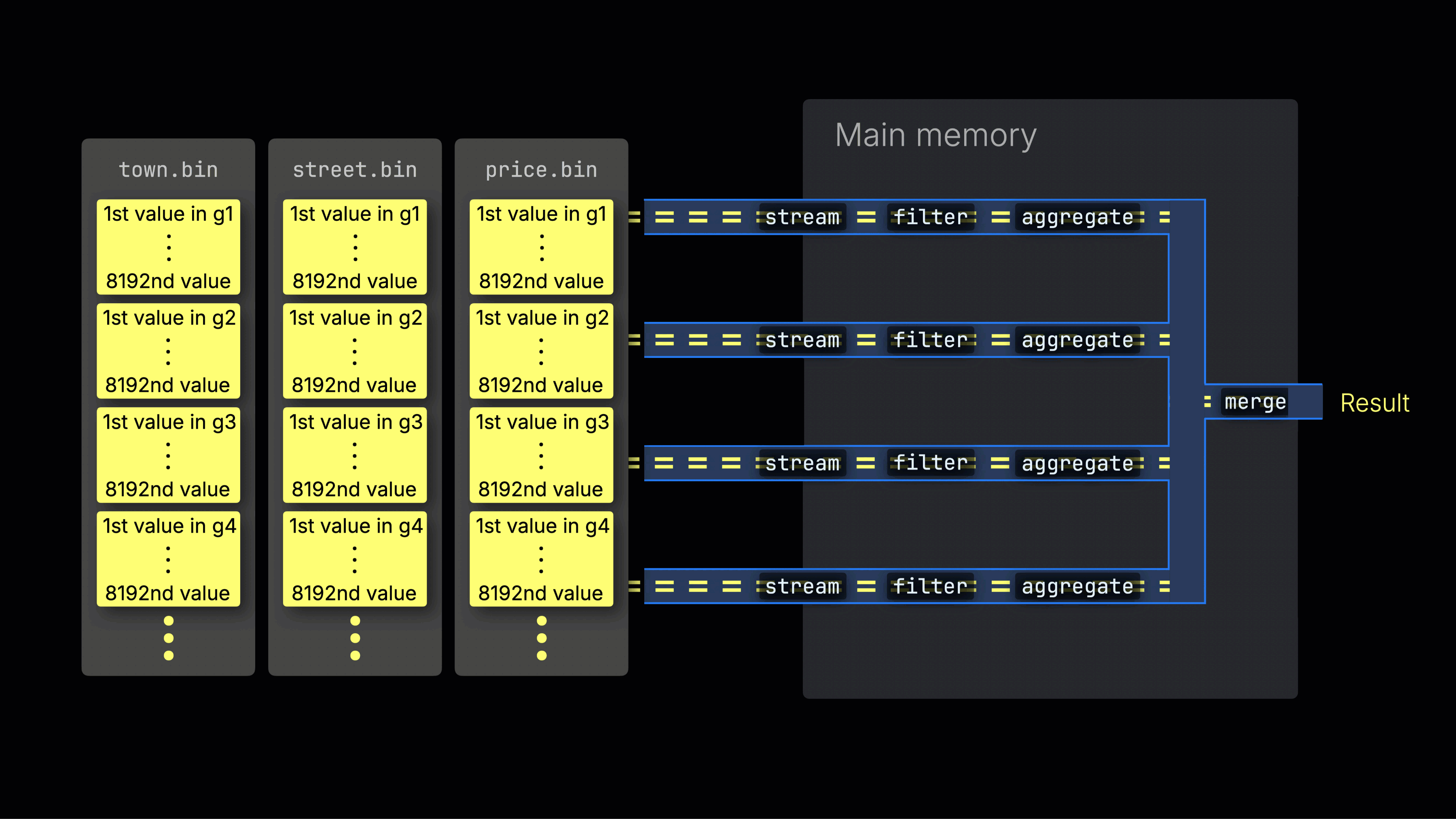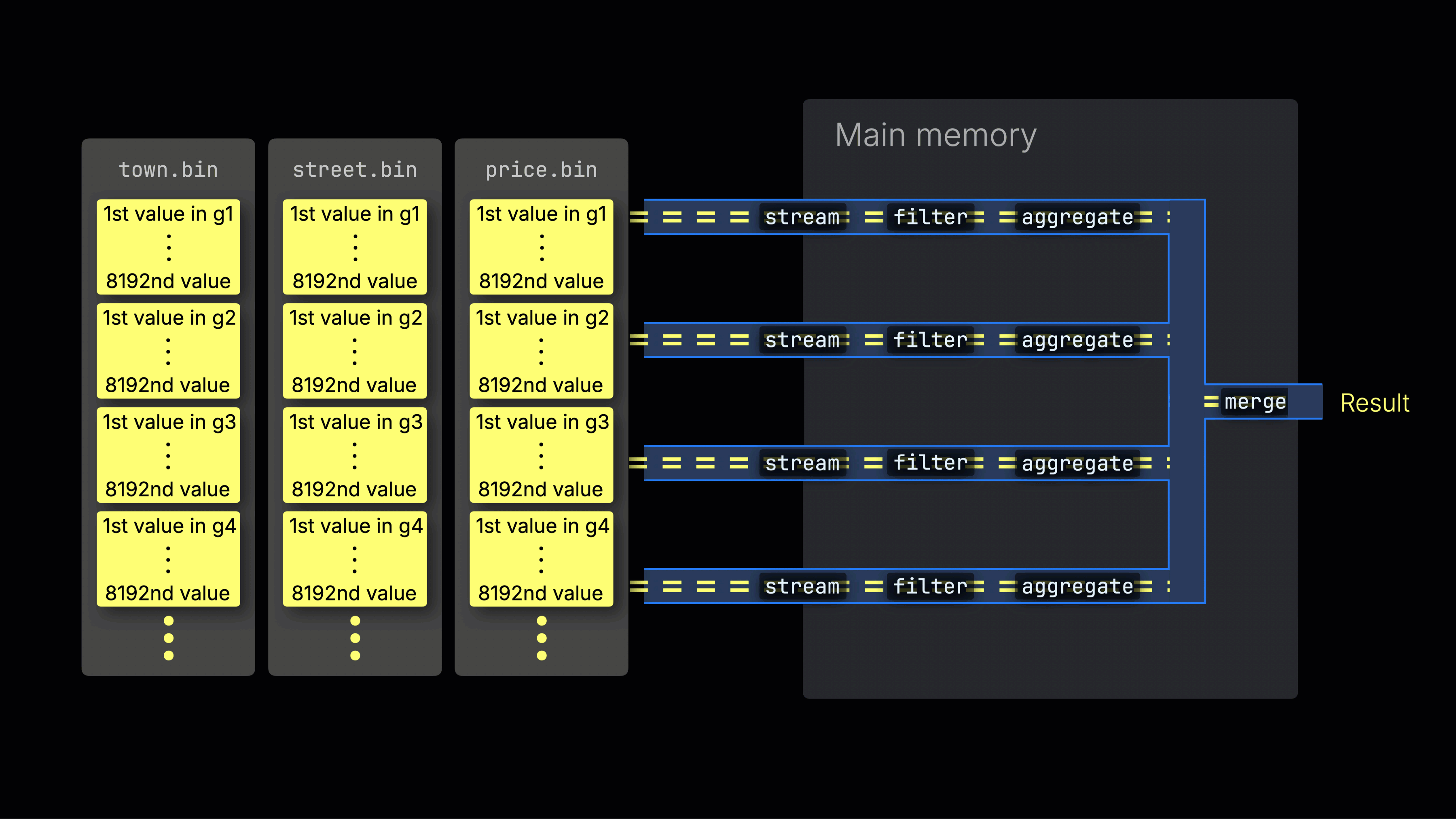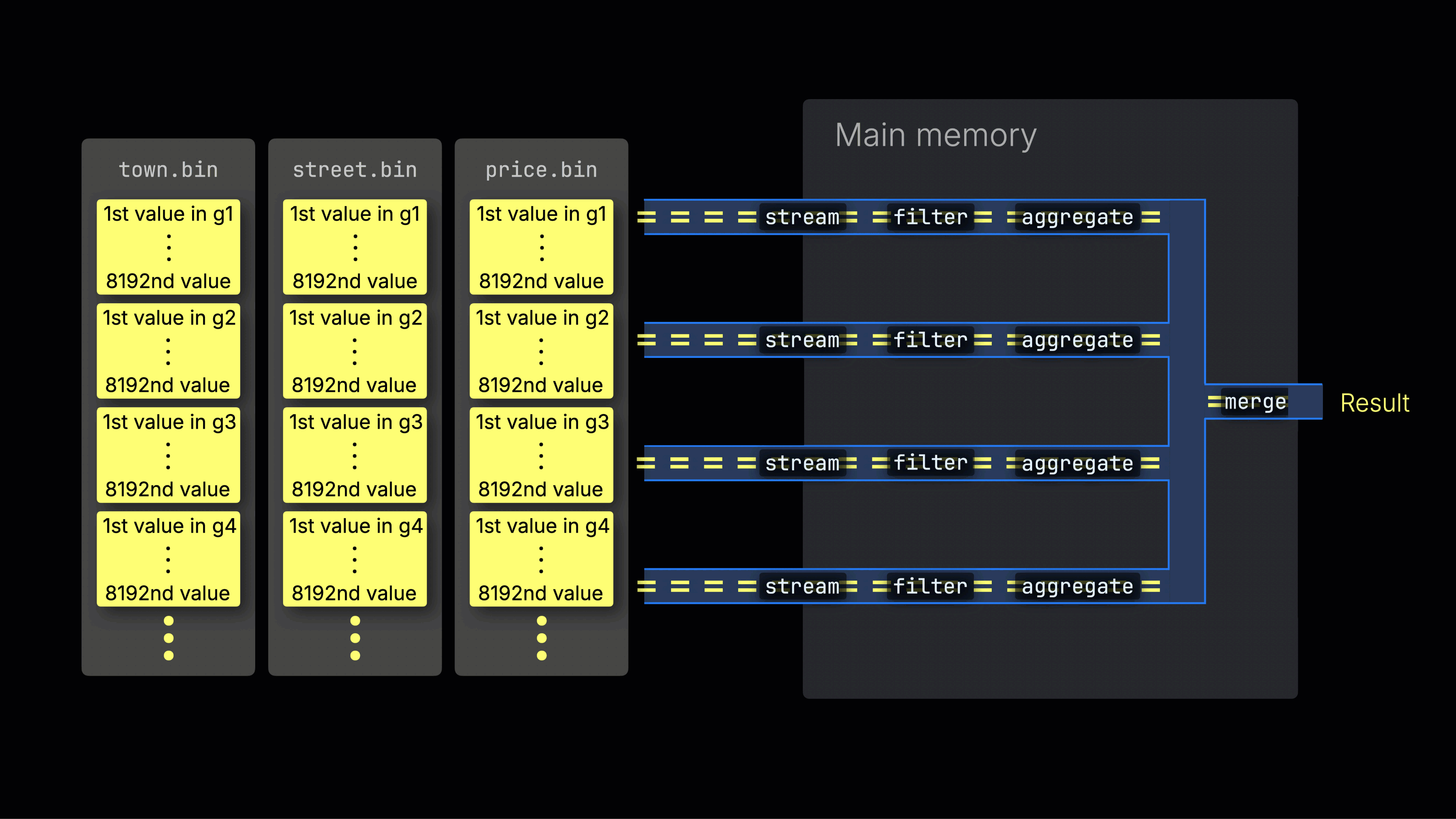
Количество n параллельных обработчиков контролируется настройкой max_threads, которая по умолчанию соответствует количеству доступных ядер CPU на сервере с ClickHouse. В приведенном примере мы предполагаем 4 ядра.
На машине с 8 ядрами пропускная способность обработки запроса примерно удвоится (но использование памяти также увеличится соответственно), так как большее количество обработчиков одновременно обрабатывают данные:
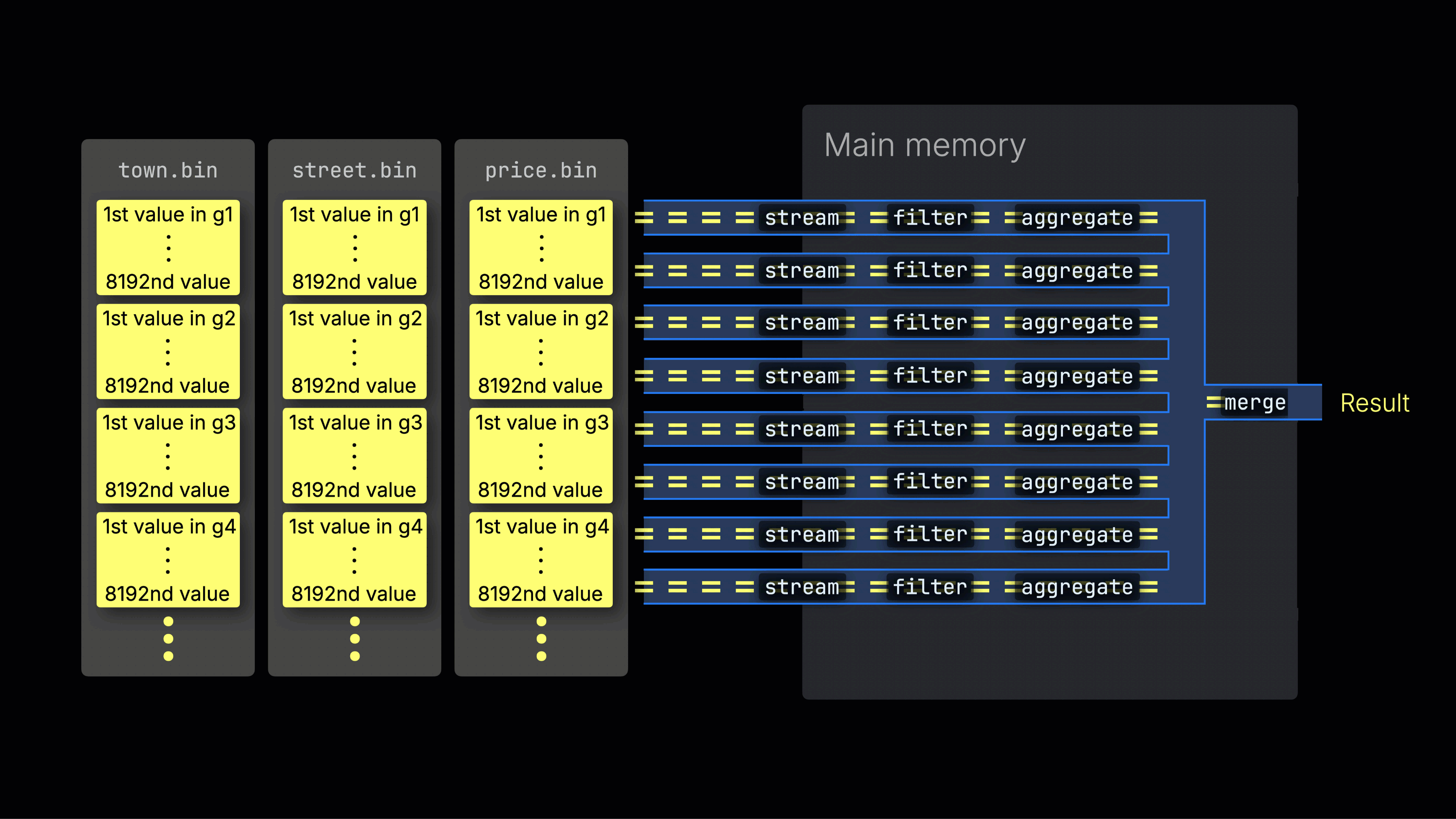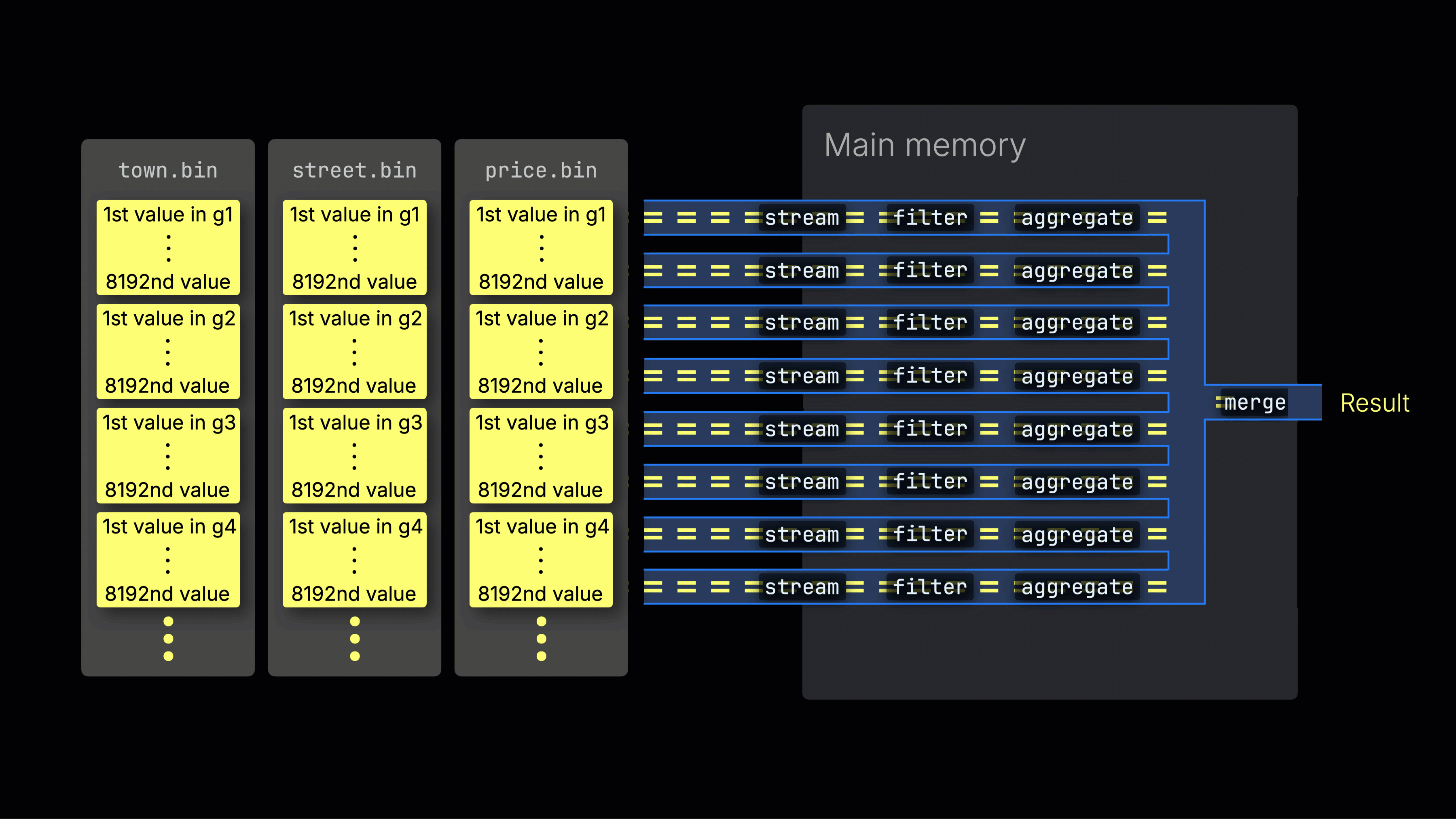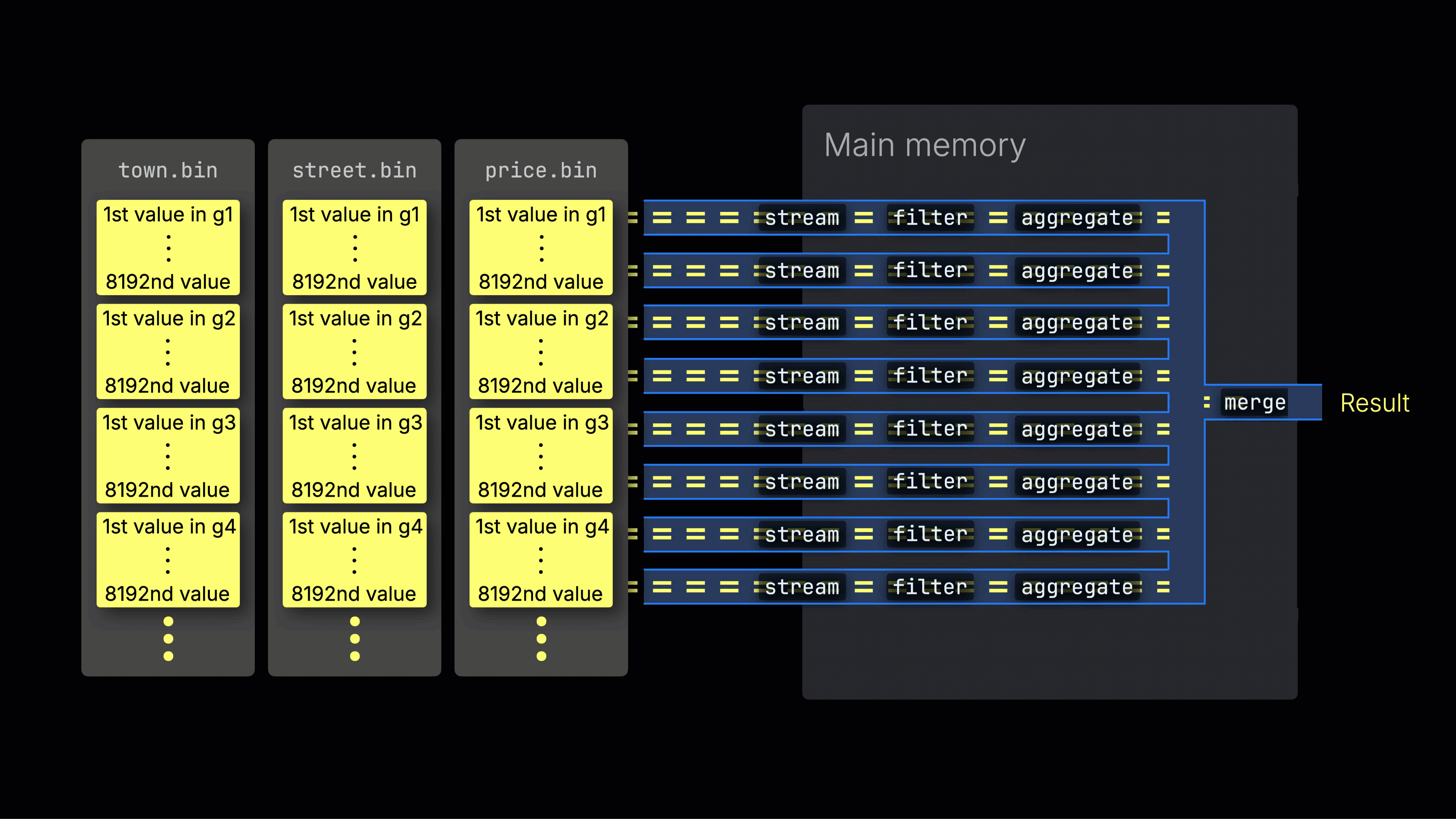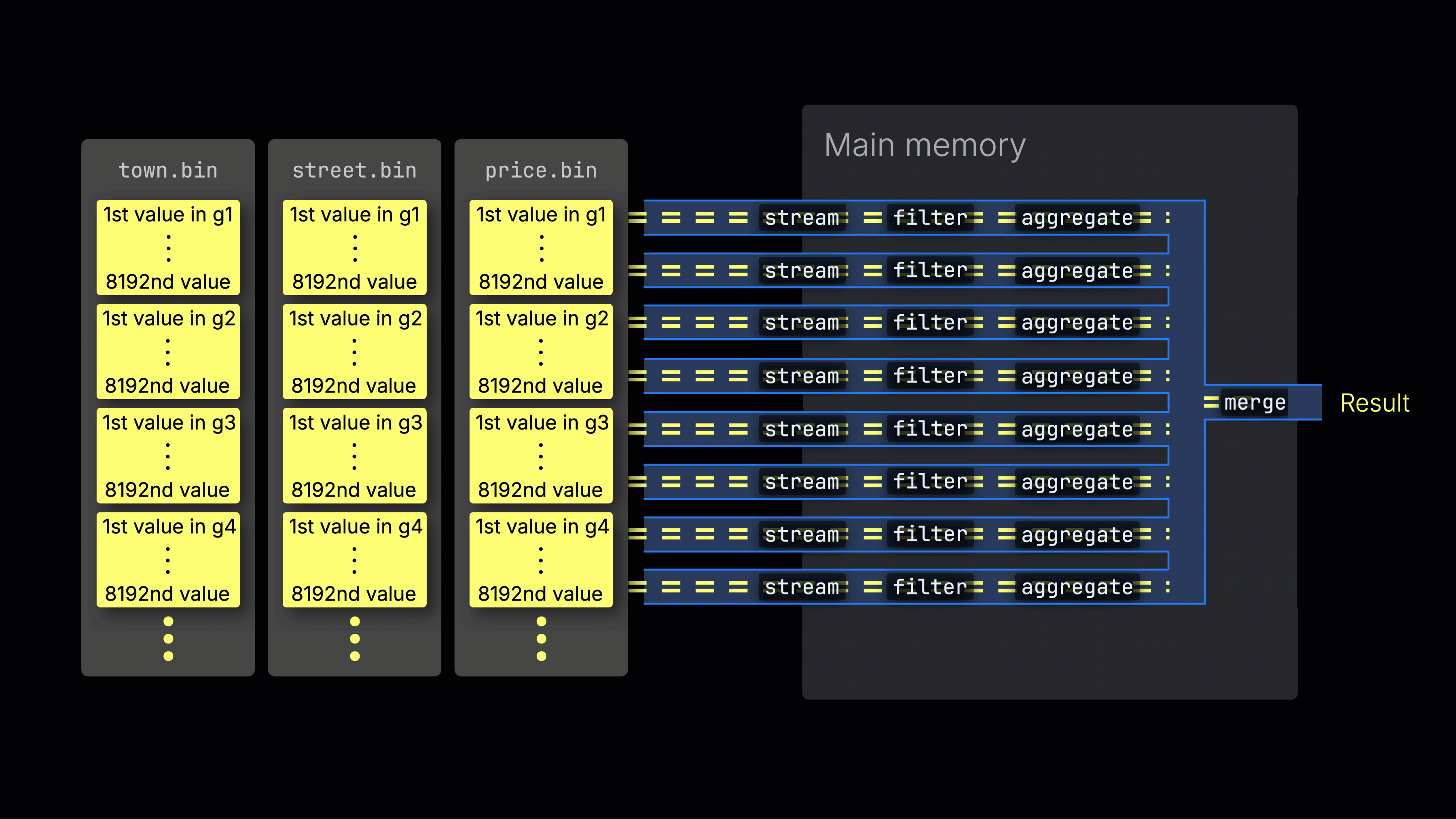
Эффективное распределение нагрузки между обработчиками является ключевым для максимизации использования CPU и сокращения общего времени выполнения запроса.
Обработка запросов к шардам
Когда данные таблицы распределены по нескольким серверам в виде шардов, каждый сервер обрабатывает свою шарду параллельно. Внутри каждого сервера локальные данные обрабатываются с использованием параллельных обработчиков, как описано выше:
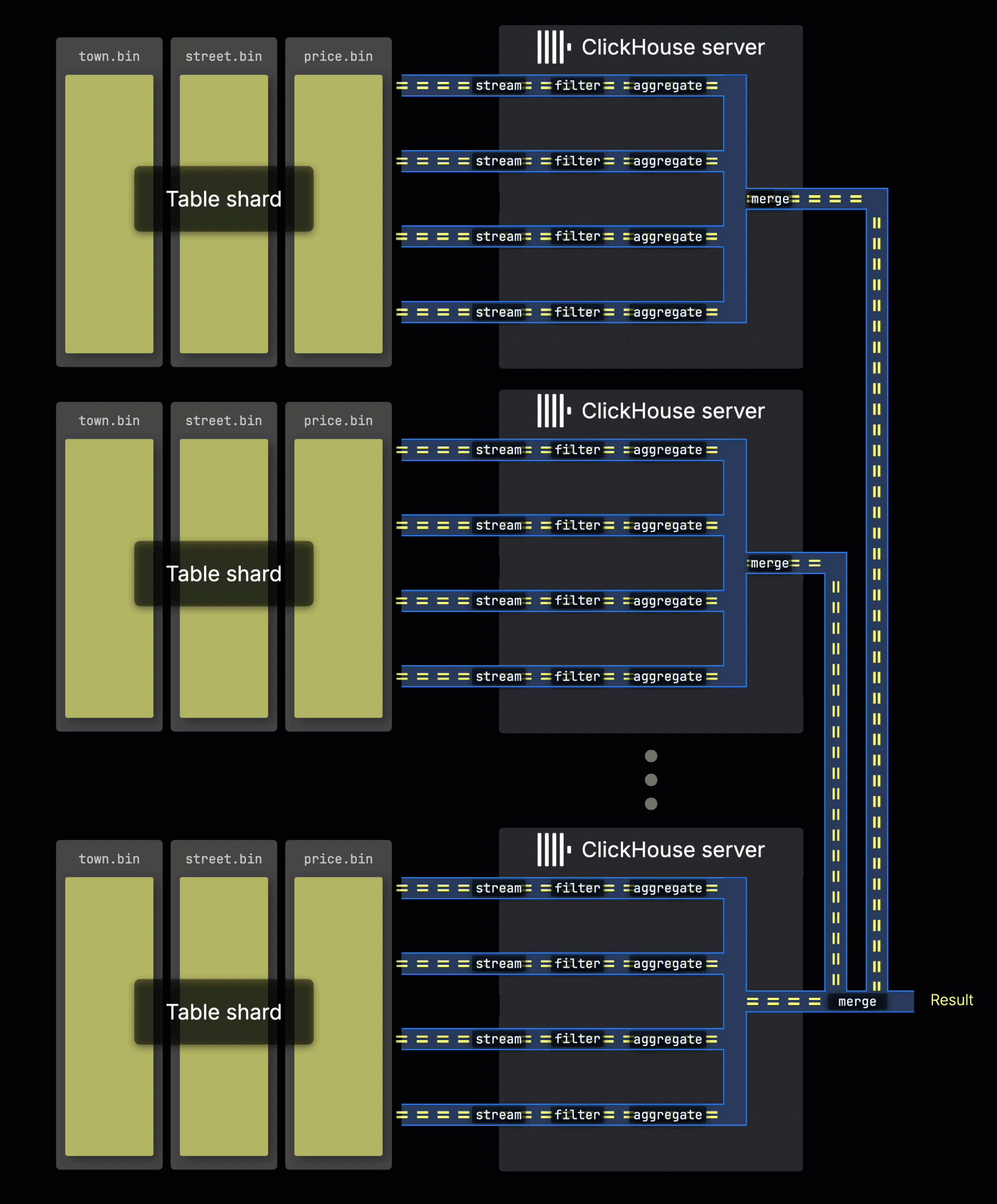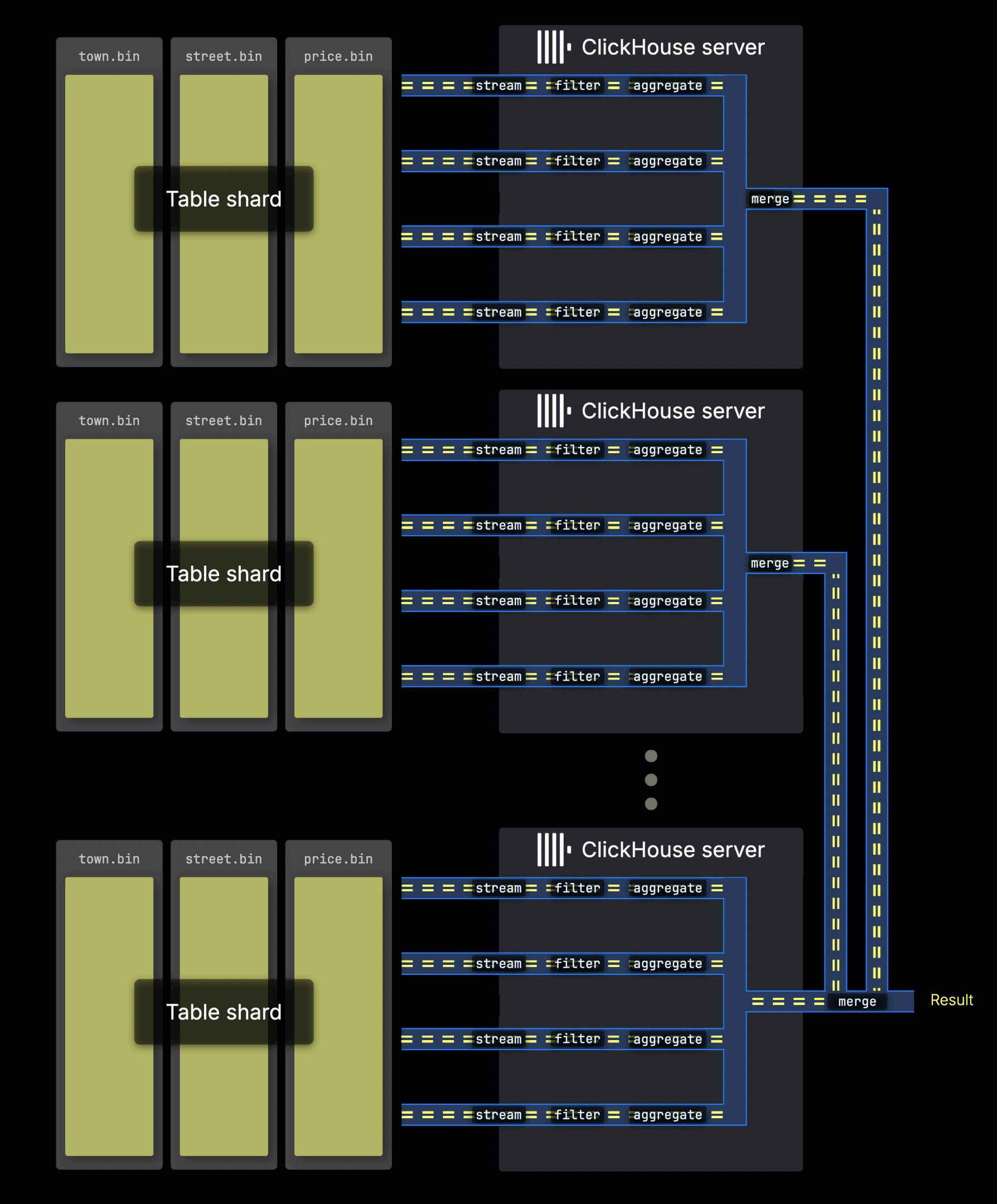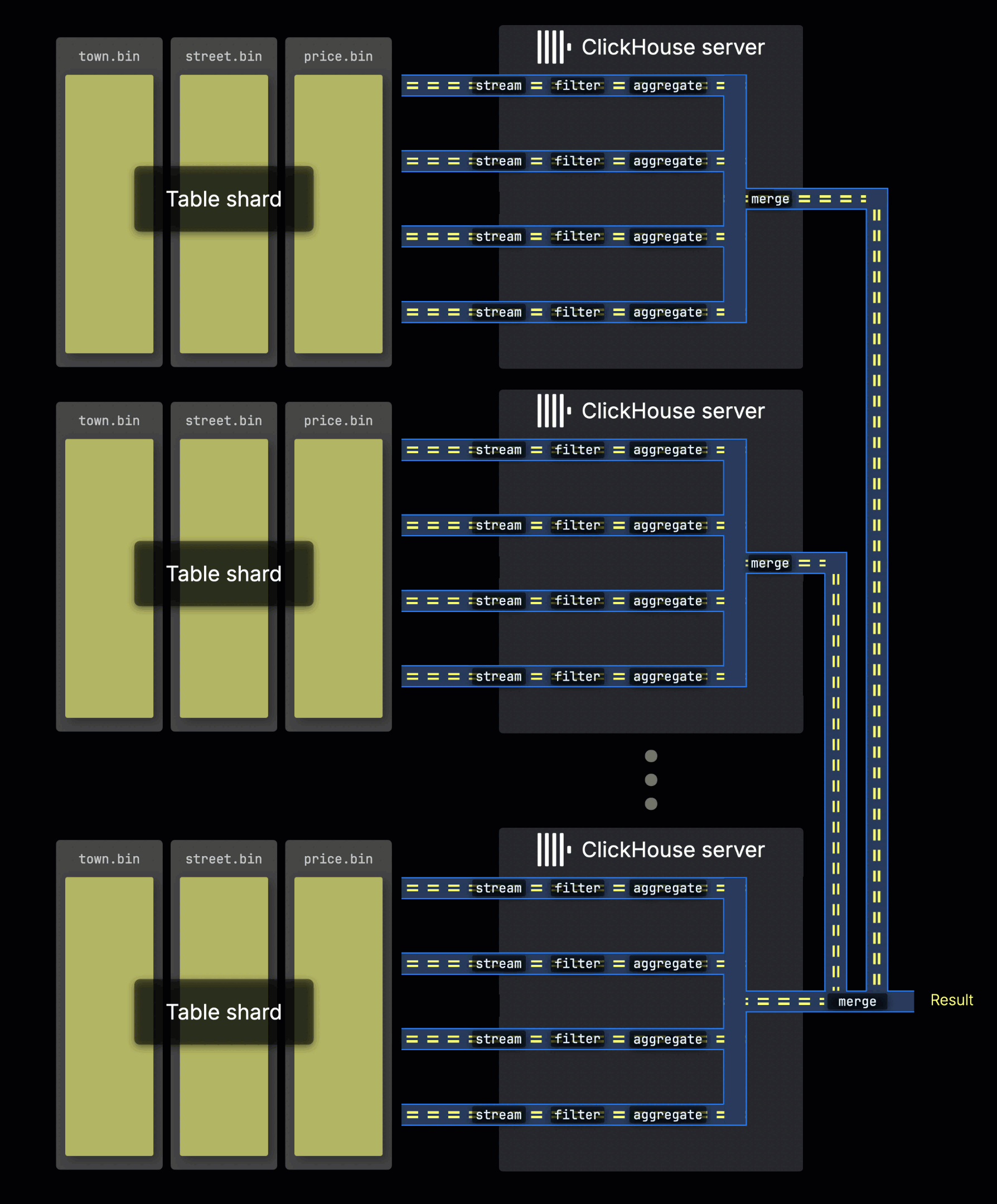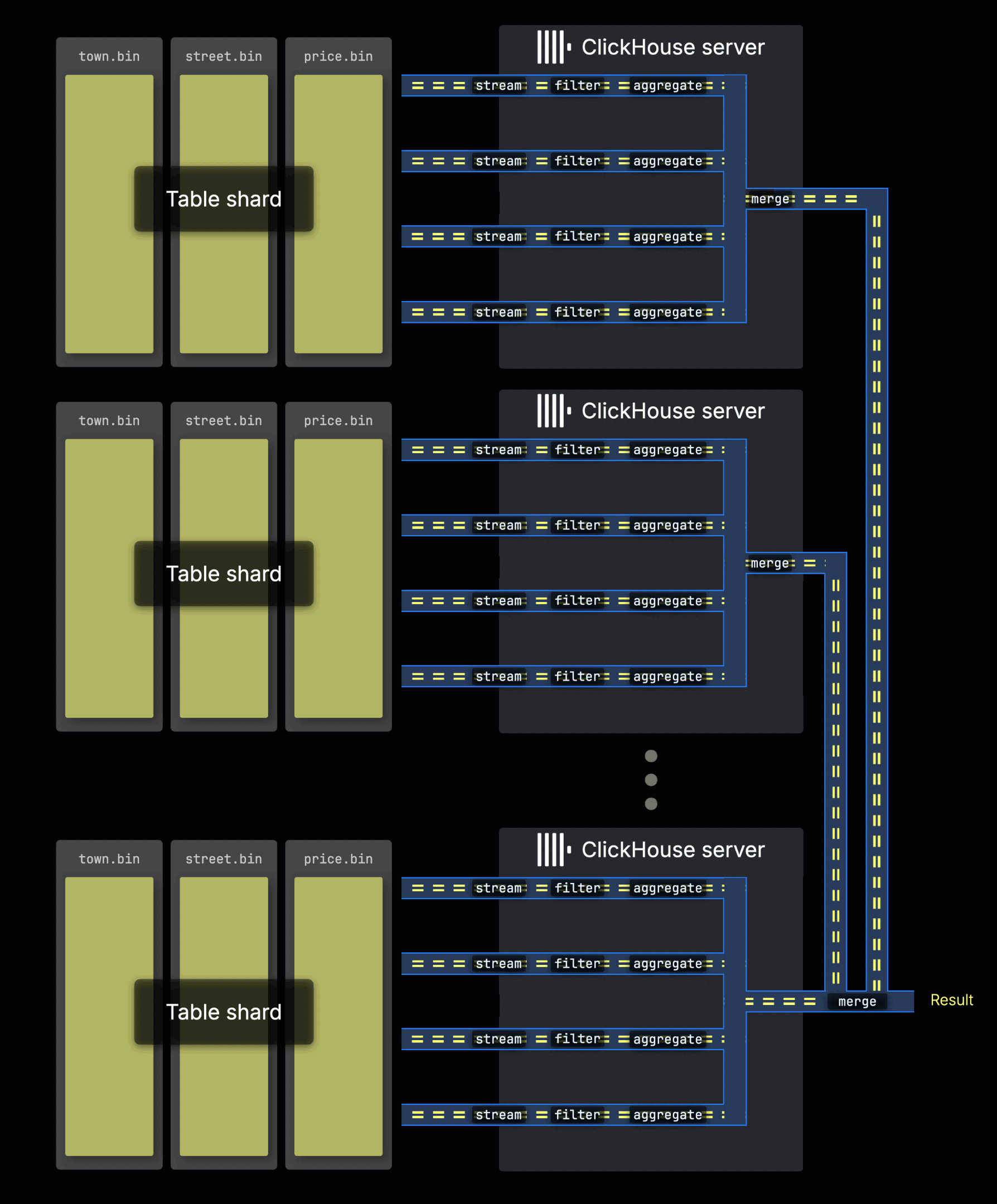
Сервер, который изначально получает запрос, собирает все подрезультаты из шардов и объединяет их в финальный глобальный результат.
Распределение нагрузки запросов между шардом позволяет горизонтально масштабировать параллелизм, особенно в средах с высокой пропускной способностью.
В ClickHouse Cloud этот же параллелизм достигается с помощью параллельных реплик, которые функционируют аналогично шардам в кластерах без общей памяти. Каждая реплика ClickHouse Cloud — это статeless вычислительный узел — обрабатывает часть данных параллельно и вносит вклад в финальный результат, как это сделала бы независимая шарда.
Мониторинг параллелизма запросов
Используйте эти инструменты, чтобы проверить, что ваш запрос полностью использует доступные ресурсы CPU и диагностировать случаи, когда это не так.
Мы запускаем это на тестовом сервере с 59 ядрами CPU, что позволяет ClickHouse полностью продемонстрировать свой параллелизм запросов.
Чтобы наблюдать, как выполняется пример запроса, мы можем указать серверу ClickHouse возвращать все записи журналов уровня трассировки во время запроса агрегации. Для этой демонстрации мы убрали предикат запроса — в противном случае обрабатывались бы только 3 гранулы, что недостаточно для ClickHouse, чтобы использовать большее количество параллельных обработчиков:
Мы можем видеть, что
- ① ClickHouse необходимо прочитать 3,609 гранул (указанных как метки в журналах трассировки) по 3 диапазонам данных.
- ② С 59 ядрами CPU он распределяет эту работу по 59 параллельным потокам обработки — по одному на каждый обработчик.
В качестве альтернативы, мы можем использовать EXPLAIN для инспекции физического плана операторов — также известного как "конвейер запросов" — для запроса агрегации:
Примечание: Читайте план операторов выше снизу вверх. Каждая строка представляет собой стадию в физическом плане выполнения, начиная с чтения данных из хранилища внизу и заканчивая финальными этапами обработки вверху. Операторы с отметкой × 59 выполняются одновременно над неперекрывающимися регионами данных по 59 параллельным обработчикам. Это отражает значение max_threads и иллюстрирует, как каждая стадия запроса параллелизована по ядрам CPU.
Веб-интерфейс ClickHouse встроенный (доступный по конечной точке /play) может отрисовать физический план из выше в виде графической визуализации. В этом примере мы установили max_threads в 4, чтобы сохранить компактность визуализации, показывая только 4 параллельных обработчика:

Примечание: Читайте визуализацию слева направо. Каждая строка представляет собой параллельный обработчик, который обрабатывает данные блок за блоком, применяя преобразования такие как фильтрация, агрегация и финальные этапы обработки. В этом примере вы можете увидеть четыре параллельные линии, соответствующие настройке max_threads = 4.
Балансировка нагрузки между обработчиками
Обратите внимание, что операторы Resize в физическом плане выше перераспределяют и перераспределяют потоки блоков данных между обработчиками, чтобы поддерживать их равномерное использование. Эта сбалансировка особенно важна, когда диапазоны данных варьируются по количеству строк, соответствующих предикатам запроса, в противном случае некоторые обработчики могут перегружаться, а другие оставаться бездействующими. Путем перераспределения нагрузки более быстрые обработчики эффективно помогают более медленным, оптимизируя общее время выполнения запроса.
Почему max_threads не всегда учитывается
Как упоминалось выше, количество n параллельных обработчиков контролируется настройкой max_threads, которая по умолчанию соответствует количеству доступных ядер CPU на сервере с ClickHouse:
Однако значение max_threads может быть проигнорировано в зависимости от объема данных, выбранных для обработки:
Как показано в извлечении из плана операторов выше, хотя max_threads установлено на 59, ClickHouse использует только 30 параллельных потоков для сканирования данных.
Теперь давайте запустим запрос:
Как показано в вышеуказанном выводе, запрос обработал 2.31 миллиона строк и прочитал 13.66MB данных. Это происходит потому, что во время фазы анализа индекса ClickHouse выбрал 282 гранулы для обработки, каждая из которых содержит 8,192 строки, в общей сложности примерно 2.31 миллиона строк:
Независимо от сконфигурированного значения max_threads, ClickHouse выделяет дополнительные параллельные обработчики только тогда, когда достаточно данных, чтобы это оправдать. "max" в max_threads относится к верхнему пределу, а не к гарантированному количеству используемых потоков.
Что означает "достаточно данных", в первую очередь определяется двумя настройками, которые определяют минимальное количество строк (по умолчанию 163,840) и минимальное количество байтов (по умолчанию 2,097,152), которые каждый обработчик должен обрабатывать:
Для кластеров без общей памяти:
Для кластеров с общим хранилищем (например, ClickHouse Cloud):
- merge_tree_min_rows_for_concurrent_read_for_remote_filesystem
- merge_tree_min_bytes_for_concurrent_read_for_remote_filesystem
Дополнительно существует жесткий нижний предел для размера задачи чтения, контролируемый:
Мы не рекомендуем изменять эти настройки в производственной среде. Они приведены здесь только для иллюстрации того, почему max_threads не всегда определяет фактический уровень параллелизма.
Для демонстрационных целей давайте проверим физический план с этими настройками, переопределенными, чтобы заставить максимальную степень параллелизма:
Теперь ClickHouse использует 59 параллельных потоков для сканирования данных, полностью соблюдая сконфигурированный max_threads.
Это подтверждает, что для запросов на небольших наборах данных ClickHouse намеренно ограничит параллелизм. Используйте переопределение настроек только для тестирования — не в производственной среде — так как это может привести к неэффективному выполнению или конкуренции за ресурсы.
Основные выводы
- ClickHouse параллелизует запросы, используя обработчики, связанные с
max_threads. - Фактическое количество обработчиков зависит от размера данных, выбранных для обработки.
- Используйте
EXPLAIN PIPELINEи журналы трассировки для анализа использования обработчиков.
Где найти больше информации
Если вы хотите глубже понять, как ClickHouse выполняет запросы параллельно и как он достигает высокой производительности в больших масштабах, изучите следующие ресурсы:
-
Слой обработки запросов – статья VLDB 2024 (веб-издание) - Подробное описание внутренней модели выполнения ClickHouse, включая планирование, конвейеризацию и проектирование операторов.
-
Объяснение частичных состояний агрегации - Техническое глубокое погружение в то, как частичные состояния агрегации позволяют эффективное параллельное выполнение через обработчики.
-
Видеоурок, подробно разбирающий все шаги обработки запросов ClickHouse:
